the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 29 Mar 2018
| 29 Mar 2018
Extracting information on the spatial variability in erosion rate stored in detrital cooling age distributions in river sands
Lorenzo Gemignani
Peter van der Beek
One of the main purposes of detrital thermochronology is to provide constraints on the regional-scale exhumation rate and its spatial variability in actively eroding mountain ranges. Procedures that use cooling age distributions coupled with hypsometry and thermal models have been developed in order to extract quantitative estimates of erosion rate and its spatial distribution, assuming steady state between tectonic uplift and erosion. This hypothesis precludes the use of these procedures to assess the likely transient response of mountain belts to changes in tectonic or climatic forcing. Other methods are based on an a priori knowledge of the in situ distribution of ages to interpret the detrital age distributions. In this paper, we describe a simple method that, using the observed detrital mineral age distributions collected along a river, allows us to extract information about the relative distribution of erosion rates in an eroding catchment without relying on a steady-state assumption, the value of thermal parameters or an a priori knowledge of in situ age distributions. The model is based on a relatively low number of parameters describing lithological variability among the various sub-catchments and their sizes and only uses the raw ages. The method we propose is tested against synthetic age distributions to demonstrate its accuracy and the optimum conditions for it use. In order to illustrate the method, we invert age distributions collected along the main trunk of the Tsangpo–Siang–Brahmaputra river system in the eastern Himalaya. From the inversion of the cooling age distributions we predict present-day erosion rates of the catchments along the Tsangpo–Siang–Brahmaputra river system, as well as some of its tributaries. We show that detrital age distributions contain dual information about present-day erosion rate, i.e., from the predicted distribution of surface ages within each catchment and from the relative contribution of any given catchment to the river distribution. The method additionally allows comparing modern erosion rates to long-term exhumation rates. We provide a simple implementation of the method in Python code within a Jupyter Notebook that includes the data used in this paper for illustration purposes.
- Article
(12200 KB) - Full-text XML
-
Supplement
(197 KB) - BibTeX
- EndNote





Thermochronometric methods provide us with information pertaining to the cooling history of a rock. Various systems and minerals provide information on different parts of that cooling history, i.e., at a given temperature but more commonly within a range of temperatures. One of the main geological processes through which rocks experience cooling is exhumation towards the cold, quasi-isothermal surface (Brown, 1991). Young ages are commonly interpreted to indicate recent or rapid exhumation whereas old ages usually correspond to ancient or slow exhumation. Cooling ages can also record more discrete cooling events such as mineral crystallization during melt solidification, the nearby emplacement of hot intrusions (Gleadow and Brooks, 1979) or the rapid relaxation of isotherms at the end of an episode of rapid erosion (Braun, 2016; Kellett et al., 2013).
Besides collecting in situ data, one can also collect and date a large number of mineral grains from a sand sample collected at a given location in a river draining an actively eroding area. Such detrital thermochronology datasets provide a proxy for the distribution of surface rock ages in a given catchment (Bernet et al., 2004; Brandon, 1992). By repeating this operation at different sites along a trunk stream, one obtains redundant information that can be used to document more precisely the spatial variability in in situ thermochronological ages in a river catchment (Bernet et al., 2004; Brewer et al., 2006).
Methods have been devised to extract quantitative information from such detrital datasets concerning the erosion history of a tectonically active area as well as estimates of its spatial variability. Ruhl and Hodges (2005) convolved their detrital age datasets with the hypsometry of the catchment to test the assumption of topographic steady state in a rapidly eroding catchment of the Nepalese Himalaya. Similarly, focusing on the eastern Sierra Nevada and White Mountains of California, respectively, Stock et al. (2006) and Vermeesch (2007) combined detrital apatite (U-Th)/He age datasets with an age–elevation relationship established from in situ samples to predict the distribution of present-day erosion rates. Whipp et al. (2009) used simulations from a thermo-kinematic model to define the limits of the applicability of such a technique, while Enkelmann and Ehlers (2015) used it in a glaciated landscape. Wobus et al. (2003, 2006) collected samples from tributaries of the Burhi Gandaki and Trisuli rivers to document the strong transition in erosion rate across a major topographic transition. By limiting their sampling to tributaries, they circumvented the need to develop and use a mixing model for the interpretation of their data. Brewer et al. (2006) derived optimal values for erosion rate in neighboring catchments by comparing and mixing theoretical probability density distributions with detrital age data from the Marsyandi River in Nepal. Resentini and Malusà (2012) used a similar approach to interpret data from the Western Alps. McPhillips and Brandon (2010) used detrital cooling ages combined with in situ age measurements to infer a recent increase in relief in the Sierra Nevada, California.
All of these methods rely on a priori knowledge or hypotheses concerning the age distributions in the catchments drained by the river from which the samples have been collected. Here we explore the possibility of deriving first-order information about the spatial variability in erosion rate in the river catchment when no such knowledge exists and without making any assumption concerning the spatial distribution of ages. We propose to regard ages as passive markers (or tracers) that inform us on the proportion in which mixing takes place today, which must be directly proportional to the present-day erosion rate. For example, the most rapid present-day erosion rates should be predicted where the age distributions change the most rapidly along the river, everything else being accounted for, such as the relative size of neighboring sub-catchments or the potential change in lithology between them. This knowledge about the distribution of erosion rates, which is obtained independently of the absolute values of the ages, can be used to estimate the distribution of ages in each sub-catchment drained by the river. This second piece of information provides additional insight into the spatial distribution of past cooling/erosional events.
In this paper, we present a method that relies on the raw age data only. This avoids any complication or bias that may arise from trying to compare the data to theoretical probability density distributions that rely on a thermal model prediction. We recognize the value of doing so, but thermal models require making assumptions about past geothermal gradients (heat flux) or rock thermal conductivity and heat production, which introduces additional uncertainty in interpreting the data. The first part of this paper describes the method. To demonstrate its accuracy and explore the limits of its applicability, we have applied the method to synthetic age datasets for which we know the erosion rate and its spatial variability. This is done in the second part of the paper. To illustrate the use of our method, we have applied it to a dataset collected in the Himalaya (along the Tsangpo–Siang–Brahmaputra river system). This is explained in the third part of the paper. There we show that the method yields reliable estimates of the distribution of present-day erosion rates in these areas as well as independent information on the spatial extent of past geological events. We conclude by suggesting potential ways in which the method could be improved. Note that the approach proposed here has been used on a set of detrital age distributions collected along the Inn River in the Eastern Alps (Gemignani et al., 2017). Gemignani et al. (2017) showed how age distributions characterized by young age peaks likely produce high estimates of present-day erosion rates when compared with catchments that contain older age peaks.
2.1 Basic assumptions
We assume that we have collected a series of age datasets measured at M specific points (or sites) along a river that drains a tectonically active region where the erosion rate is likely to vary spatially. We also assume that the datasets have been used to construct age distributions decomposed into N age bins (see Fig. 1) that may, for example, correspond to given, known geological events or, alternatively, have been selected after constructing a kernel density estimate of the data (Vermeesch, 2012) and applying a mixture model to infer potential discrete age peaks in the age distribution (Sambridge and Compston, 1994). Although each bin corresponds to an age range, it might be easier to refer to it as representative of a given “age”, which can be taken as the mean age of the range, for example. We will call for and the relative height of bin k in distribution i. Because these are relative contributions, we have
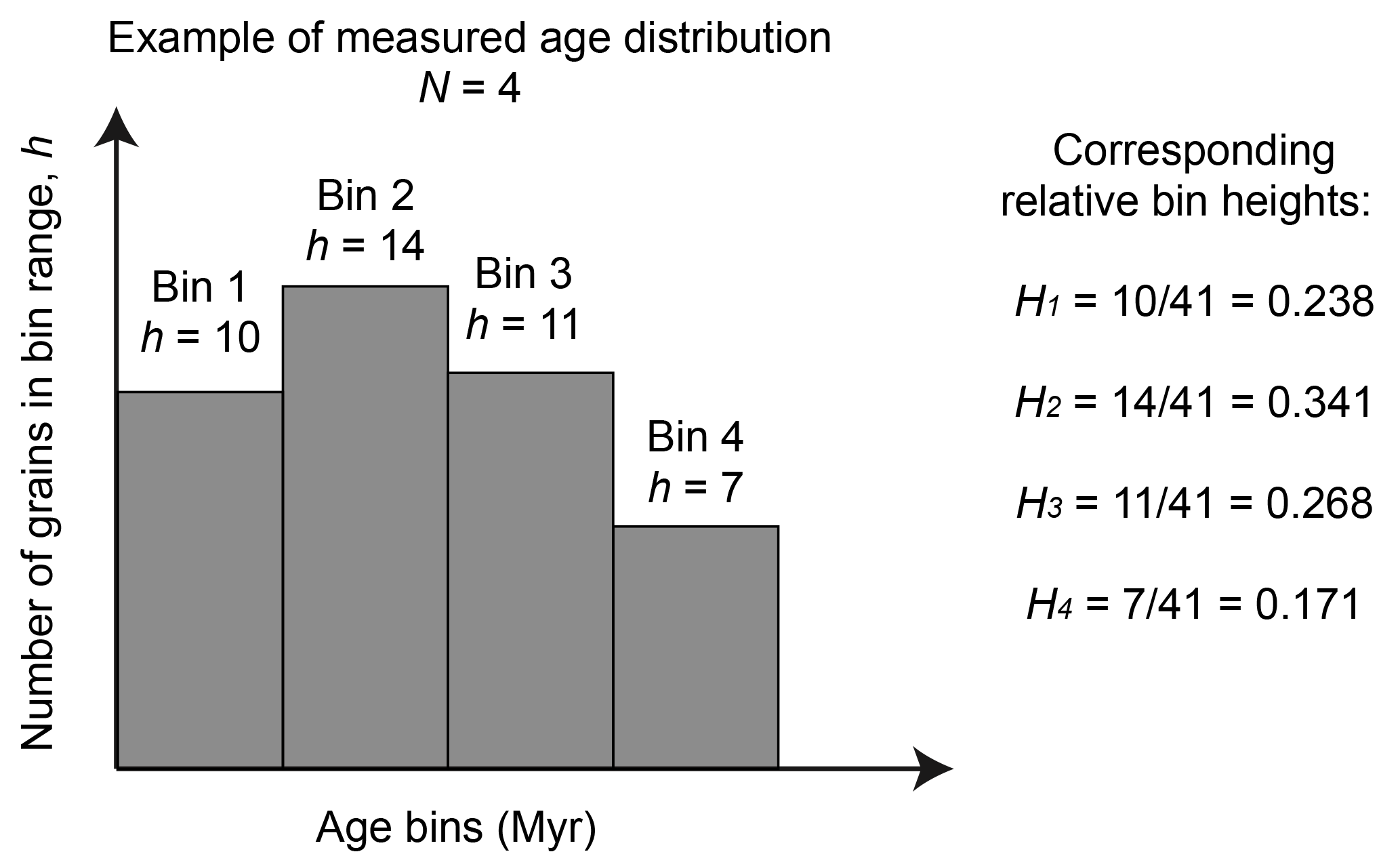
Figure 1Example of a measured age distribution and the relative heights of the corresponding bins (N=4 in this example).
The landscape is divided into exclusive contributing areas for each of the points along the main river where we have measured a dataset and compiled a distribution from it. We take the convention that Area 1 (of surface area A1) is the area contributing to site 1, whereas Area 2 (of surface area A2) is the area contributing to site 2 but not to site 1. Area i (of surface area Ai) therefore contributes to site i but not to the previous i−1 sites (see Fig. 2). In each Area i, we will assume that αi is the relative abundance of the mineral used to estimate the age distribution in rocks being eroded from the surface. We will call αi the “mineral concentration factor” of Area i. We take the convention that , with αi=1 corresponding to an area i with surface rocks that contain the mineral in abundance and αi=0 corresponding to an area i with surface rocks that do not contain the mineral. We also call ϵi the unknown present-day mean erosion rate in Area i.
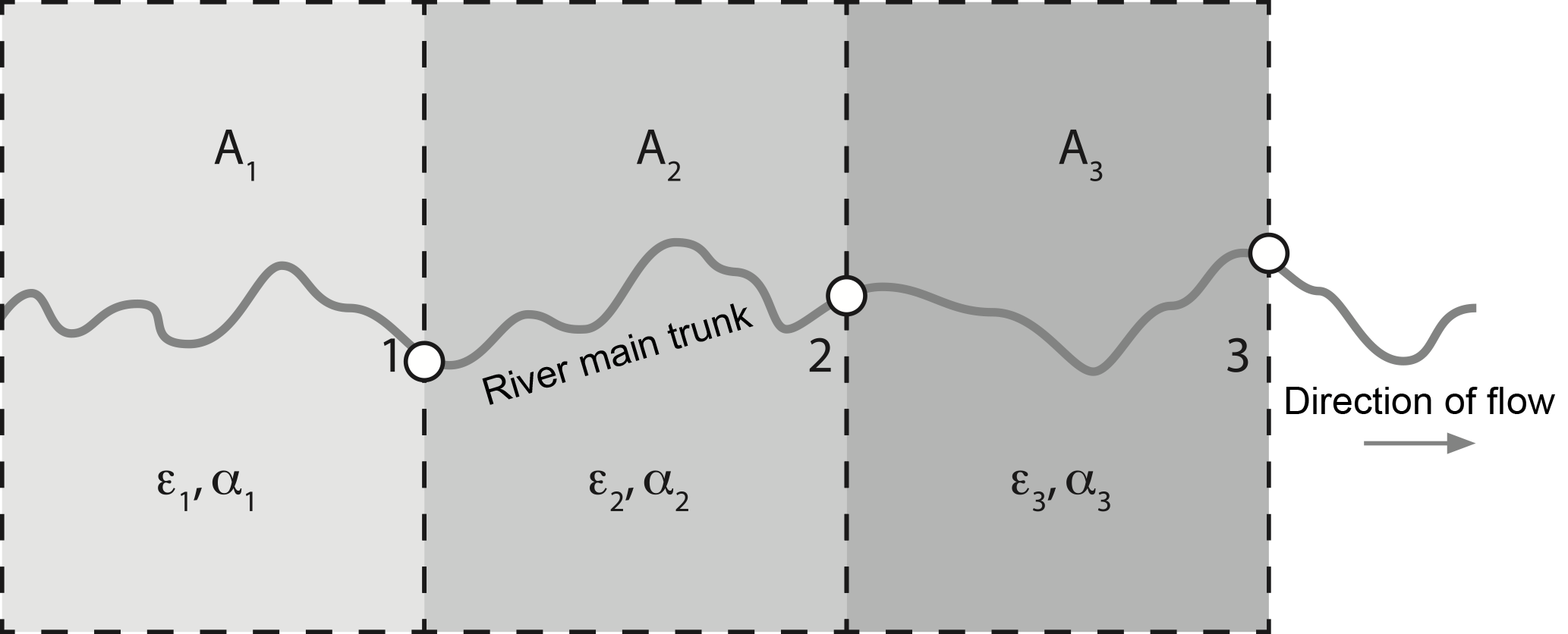
Figure 2Schematic representation of how the landscape is divided into exclusive contributing areas Ai (different shades of gray) for each of the points (here the circles labeled ) along the main river where we have age distributions. ϵi and αi are the assumed mean erosion rate and mineral concentration factor of Area i, respectively.
The surface areas, Ai, can be computed from a digital elevation model. The value of the concentration factors depends on the regional geology. First-order estimates of the αi parameters can be derived by considering the relative occurrence of the specific mineral-bearing rocks in each area from a geological map. However, recent work shows that mineral abundance in river sediments can vary significantly between tectonic units with similar lithology (Malusà et al., 2016). In their work, Malusà et al. (2016) propose a quantitative approach that can be used to infer potential “mineral fertility” bias between adjacent catchments and provide an example from the Alps. It is not the purpose of this paper, however, to speculate on the bias induced by the mineral fertility parameter in the interpretation of detrital age distributions. We refer to previous work such as that of Malusà et al. (2016) or Resentini and Malusà (2012) on the subject and assume that if the necessary data are available to perform a correction for this bias, it should be made by adjusting the value of the mineral concentration factor αi accordingly.
From these simple assumptions, we can write that the number of grains of age k coming out of catchment i is given by
where Fi=Aiαi and represents the unknown relative concentration of grains of age k in surficial rocks in Area i. We also have
because also represents relative or normalized concentrations. The relative concentrations, , tell us to what extent age k has been preserved in surficial rocks of Area i, whereas ϵi is a measure of present-day erosion rate in Area i.
2.2 Downstream bin summation along main trunk
We can now write that the predicted height of bin k in the distribution observed at site i should be equal to the total number of grains of age bin k coming from all upstream areas divided by the total number of grains of all ages coming from all upstream areas:
We can slightly rearrange this to obtain
If we divide the numerator and denominator of this expression by F1ϵ1, we obtain
where
is the contribution from Area j relative to Area 1. Note that, if we assume that we can confidently estimate Fj=Ajαj, ρj becomes a measure of the unknown erosion rate, ϵj, in Area j relative to the unknown erosion rate, ϵ1, in Area 1.
2.3 Incremental formulation
We now express Eq. (6) as an incremental relationship between and only, i.e., between the relative bin heights of distributions measured at two successive points along the main trunk. From Eq. (6), we can write
and by dividing numerator and denominator by , we obtain
where
is the contribution of Area i relative to the contribution of all upstream areas, i.e.,, what sediment is entering the river from Area i relative to what is already in the river. We will call δi the “relative contribution” from Area i.
We can also write
From this relationship we see that the relative changes in bin height between two successive sites along the main stream contain information about the present-day erosion rate in the intervening catchment, through the relative contributions δi and the relative concentrations in surface bedrock in Area i, . If one knows either δi or the (for ), one can derive the value of the other quantity/quantities. For example, Resentini and Malusà (2012) assumed that they knew the values of the surface concentrations in each sub-catchment to derive estimates of the corresponding δi. Here we will try to assess whether the values of both the relative surface concentrations and the relative contributions can be estimated.
2.4 Estimating erosion rates
Considering that we have M sites along the main river trunk and that we have selected to use N bins to describe the distributions of ages, we have N×M unknown values for the relative heights of the bins describing the distribution of ages in the source areas (the ) and another set of M−1 unknown values for the relative contributions δi. However, we only have N×M equations (see Eq. 11), and the problem is clearly underdetermined; i.e., we have more unknowns than equations among the unknowns. This means that there is an infinite number of solutions that satisfy the equations. We cannot estimate the values of all unknowns, but, as we will show now, we can estimate bounds on the value of the unknowns δi.
Two cases must be considered. First, if there is a noticeable change in relative bin heights in the detrital record between sites i−1 and i, i.e., , the distribution of ages in Area i, , must be different from that in the river at site i, i.e., , and, consequently, the relative contribution from Area i, δi must be finite, i.e., δi>0 and therefore ϵi>0. This means that there must be a minimum finite value for δi and therefore for ϵi to explain the difference in distribution between sites i−1 and i. We will call this the minimum but finite value (and , respectively). There is another solution to consider where δi→∞ and , which is correct regardless of the values of the and which corresponds to the situation where the relative contribution from Area i is so large that it completely overprints the river signal. We thus have two bounds for the relative contributions δi at each site, one finite and the other infinite:
The second case to consider is when the relative bin heights between two successive sites do not change , i.e., for all bins k. In this case, we cannot tell if this is because the erosion rate in catchment i is zero () or because the signature of the source in catchment i, i.e., the distribution of ages at the surface, is identical to that of the river (), and we have no constraints on δi or the erosion rate in Area i. Although this situation may arise, we will now only consider the case where and try to find the value of .
For this, we rewrite Eq. (11) as
represents relative bin heights, i.e., and . This implies that also represents relative bin heights. Therefore we must have and . This leads to two constraints on the value of the relative contribution δi:
and
for all . The first condition applies where there is a decrease in any relative bin height k between site i−1 and site i, i.e., , whereas the second condition applies where there is an increase in any relative bin height k between locations i−1 and i, i.e., . We can therefore conclude that the minimum values of the contribution factors that are necessary to explain the change in relative bin size from site to site are given by
From these estimates of the contribution factors, , we can then derive the value of the corresponding erosion rate in each Area i, , that is necessary to explain the observed variations in age distributions along the main river trunk, by using the following relationship that we derive in the Appendix:
assuming that and such that the estimated minimum erosion rates are relative erosion rates scaled by the unknown erosion rate in the first catchment.
From the values of the minimum contribution factors, , we can also estimate the relative surface concentrations of each age bin k in each catchment i, using
Age distributions from tributaries can be included to improve the solution locally, i.e., in the tributary catchment. Let us call AT, αt and ϵT the catchment area, the mineral concentration factor and the mean erosion rate of the tributary catchment and AM, αM and ϵM the catchment area, the mineral concentration factor and the mean erosion rate of the rest of catchment i.
For each bin k in the catchment i, we can write
where FT=ATαT and FM=AMαM. By conservation of eroded rock mass, we have
which we can use to transform Eq. (19) into
to obtain
Using the method for the main trunk data described in the previous sections, we know ϵi and . The tributary data (age distributions) gives us the surface concentrations as measured in the tributary stream (i.e., ) and we can solve for the surface concentrations assuming first that the erosion rate is uniform in the catchment i, i.e., , to give
However, this may lead to unrealistic values of the relative surface concentrations , i.e., not comprised between 0 and 1. Consequently, two conditions need to be added so that for all k. The first condition () yields
while the second condition () yields
The true erosion rate must satisfy both conditions and we therefore select the smallest value of ϵT obtained by considering any relative surface concentration difference between the tributary sub-catchment concentration () and that of the entire catchment ().
3.1 Uncertainty estimates by bootstrapping
We assess the robustness of our estimates of minimum erosion rate and corresponding relative concentrations , derived from finite size samples by bootstrapping. For this, we simply use the method described above on a large number of subsamples of the observed distributions constructed by random sampling of the observed distributions with replacement. This yields distributions of erosion rate and relative concentrations that can be used to estimate the uncertainty arising from the finite sample size. These distributions are usually not normal and we use their median value rather than their mean as the most likely estimate of erosion rate and their standard deviation to represent uncertainty.
The code is provided as a Jupyter Notebook containing python code and explanatory notes that refer to the equations given in this paper. The user must provide a series of input files containing (a) the description of the sites, i.e., the order in which the sites are located along the river, whether they drain into the main river stem or into a tributary, the drainage area A, and the mineral concentration factor α, (b) the bin sizes and (c) the observed age data at each site. The code produces distributions of estimates of erosion rate and relative concentration of grains of ages within each bin for each site from the bootstrapping.
We have assessed the reliability of the erosion rate estimates obtained from the method by applying it to synthetic age distributions made of N=4 age bins at M=5 sites. We have assumed known mineral concentration factors, αi, contributing areas, Ai, and relative erosion rates. To construct the distributions, we created very large samples (106 grains) from normal distributions of grains having ages centered on four peak values (20, 40, 60 and 80 Myr) with a standard deviation of Δa=5 Myr. The amplitude of the peaks is first set to , , , and , for the five sites. In this way, we are likely to maximize relative bin height differences between two consecutive sites. We will later relax this assumption and see how it impacts the estimates obtained by the method. We then constructed five grain distributions corresponding to each of the sites by adding the original distributions in proportions given by the relative contributions (product of area, mineral concentration factor and erosion rate) of each area. We then sampled these distributions by randomly selecting n=100 grains. This number was chosen because, in many detrital age studies, it represents the average number of grains collected at any given site. We applied our method to these synthetic datasets to obtain distributions of minimum erosion rate by bootstrapping and took the median value as a reliable estimate of the minimum erosion rate in each area necessary to satisfy the synthetic age distributions. We repeated this operation 1000 times (i.e., by generating 1000 synthetic datasets) to obtain the distributions of estimates of minimum erosion rates and compared them to the imposed erosion rates used to construct the synthetic age distributions. In a first set of four experiments, the areas and mineral concentration factors are identical for each site. In the first experiment, the erosion rates are chosen to vary greatly (by up to 2 orders of magnitude) between consecutive sites. In the second experiment, all sites have the same erosion rate; in the third experiment, the erosion rate increases by a factor of 2 from site to site, and in the fourth experiment, the erosion rate decreases by a factor of 2 from site to site. The results are shown in Fig. 3.
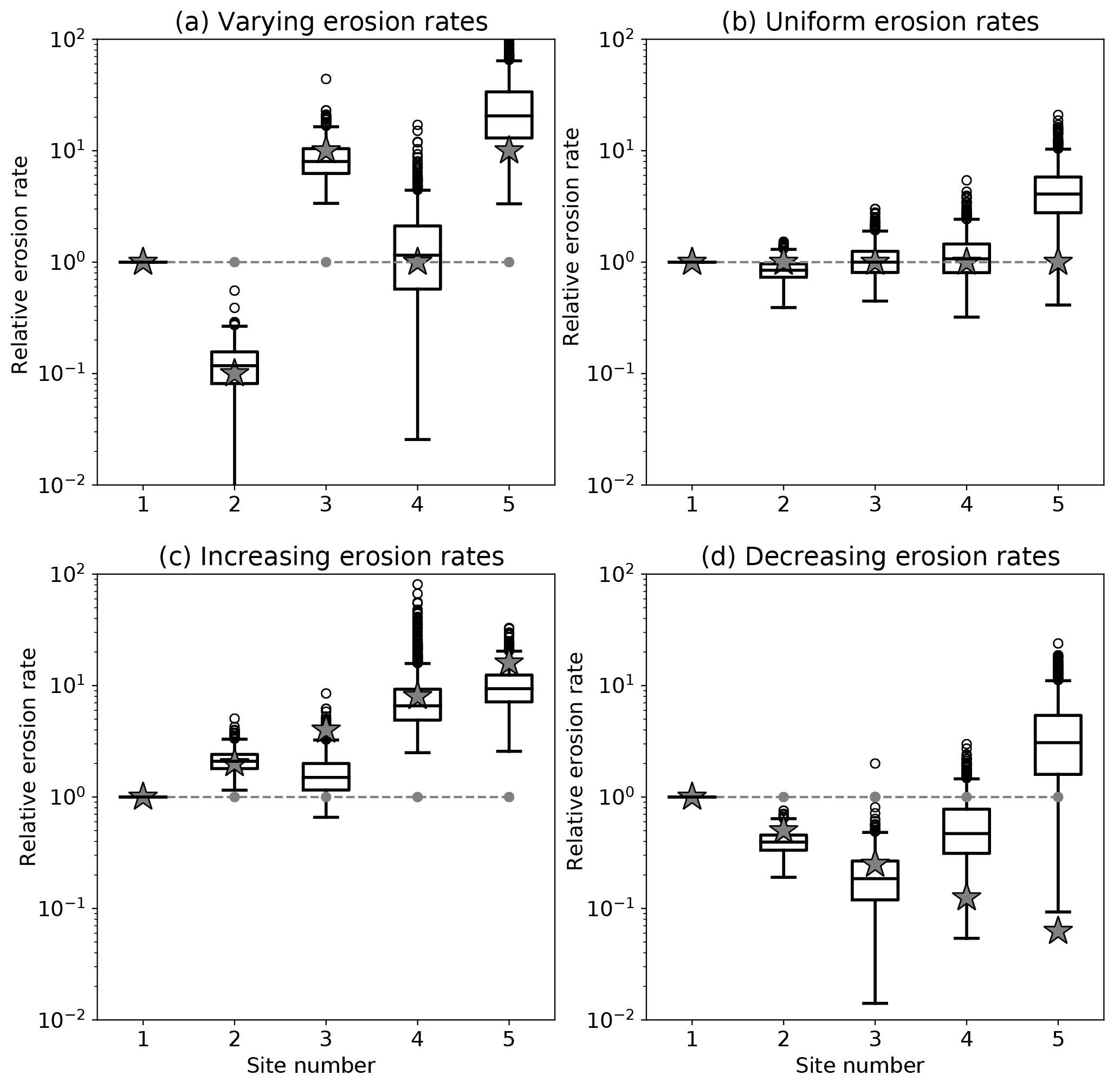
Figure 3Results of the method applied to the first set of synthetic datasets. Computed erosion rate distributions for four synthetic datasets. For each distribution, the box extends from the lower to upper quartile values, the line corresponds to the median value, and whiskers extend from the box to show the range of the erosion rate estimates, excluding outliers. Outliers are indicated by small circles past the end of the whiskers. For each site, the gray stars correspond to the imposed erosion rates and the dashed gray line gives the product of the imposed area and fertility factors, Fi=Aiαi.
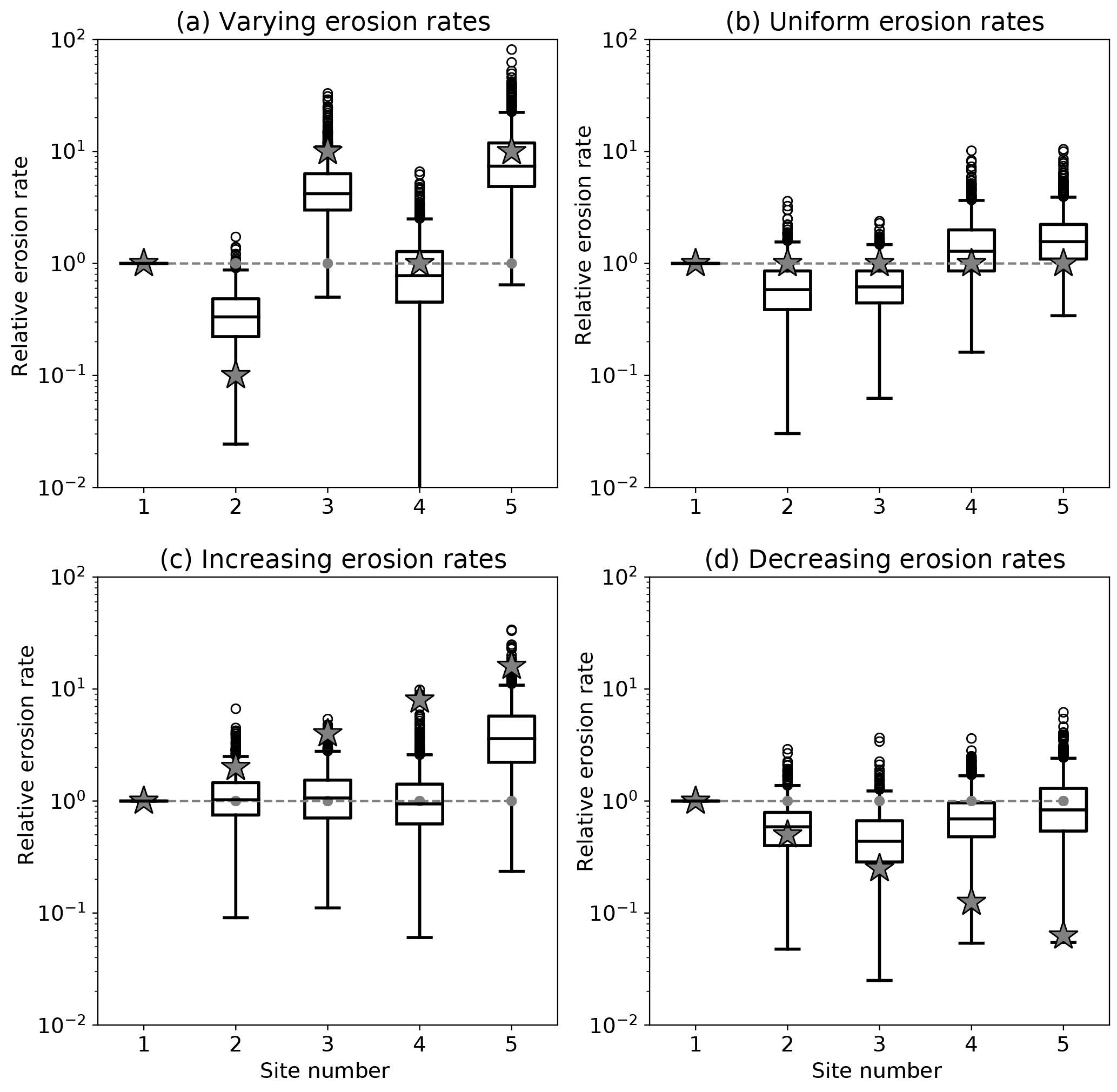
Figure 4Results of the method applied to the second set of synthetic datasets with random peak amplitudes. See Fig. 3 caption for further details.
We see that the estimated erosion rates (median value) are in good agreement with the imposed (true) erosion rates, especially when large jumps in erosion rate exists between successive sites/catchments. However, in some cases, there appears to be an artificial increase in estimated erosion rate from site to site. This is clearly seen in the case where the imposed erosion rate is assumed to be uniform at all sites or to decrease from site to site. In both cases, the method predicts an apparent (or spurious) increase in erosion rate at the last site.
To determine what controls the reliability of these estimates, we performed two other sets of experiments. The first assumes random amplitudes for the peaks in each of the catchments (Fig. 4), and the second assumes that Fi (product of drainage area Ai by relative abundance αi) increases downstream (Fig. 5). When the amplitudes of the peaks are random, the differences in peak height between two successive sites is much smaller, leading to deteriorated values for the estimated erosion rates. Conversely, when the contributing areas (or relative abundances) increase downstream, the estimates are improved.
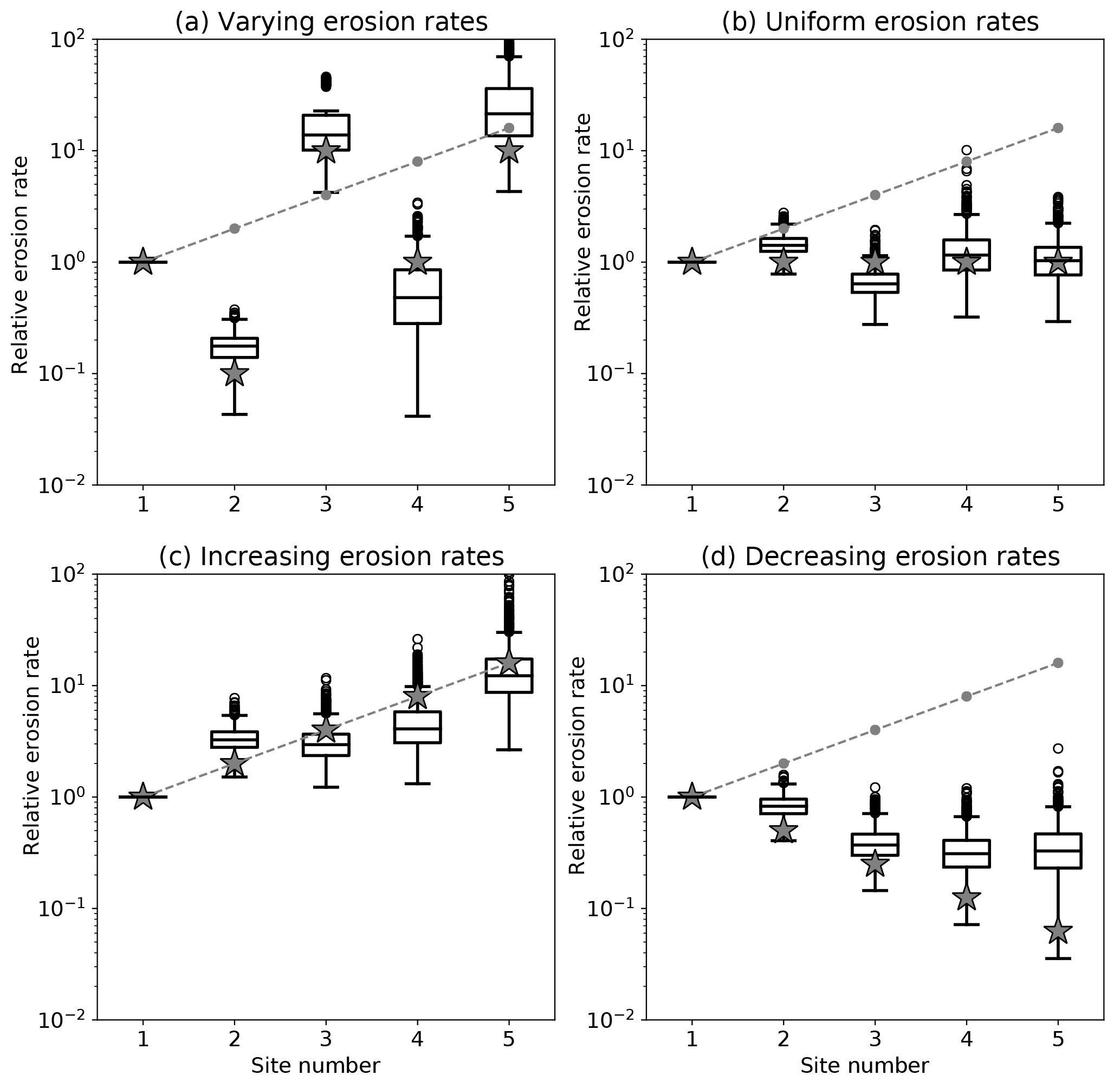
Figure 5Results of the method applied to the second set of synthetic datasets with increasing Fi=Aiαi downstream. See Fig. 3 caption for further details.
Table 1Age bins used to construct age distributions shown in Fig. 8 and used in our example.

Consequently, the accuracy of the estimates of erosion rate obtained from our method rely on whether the two successive age distributions used to estimate the are markedly different and whether the size of the two successive catchments increases or, at least, does not decrease substantially. These conditions should be kept in mind when interpreting the results obtained by our method.
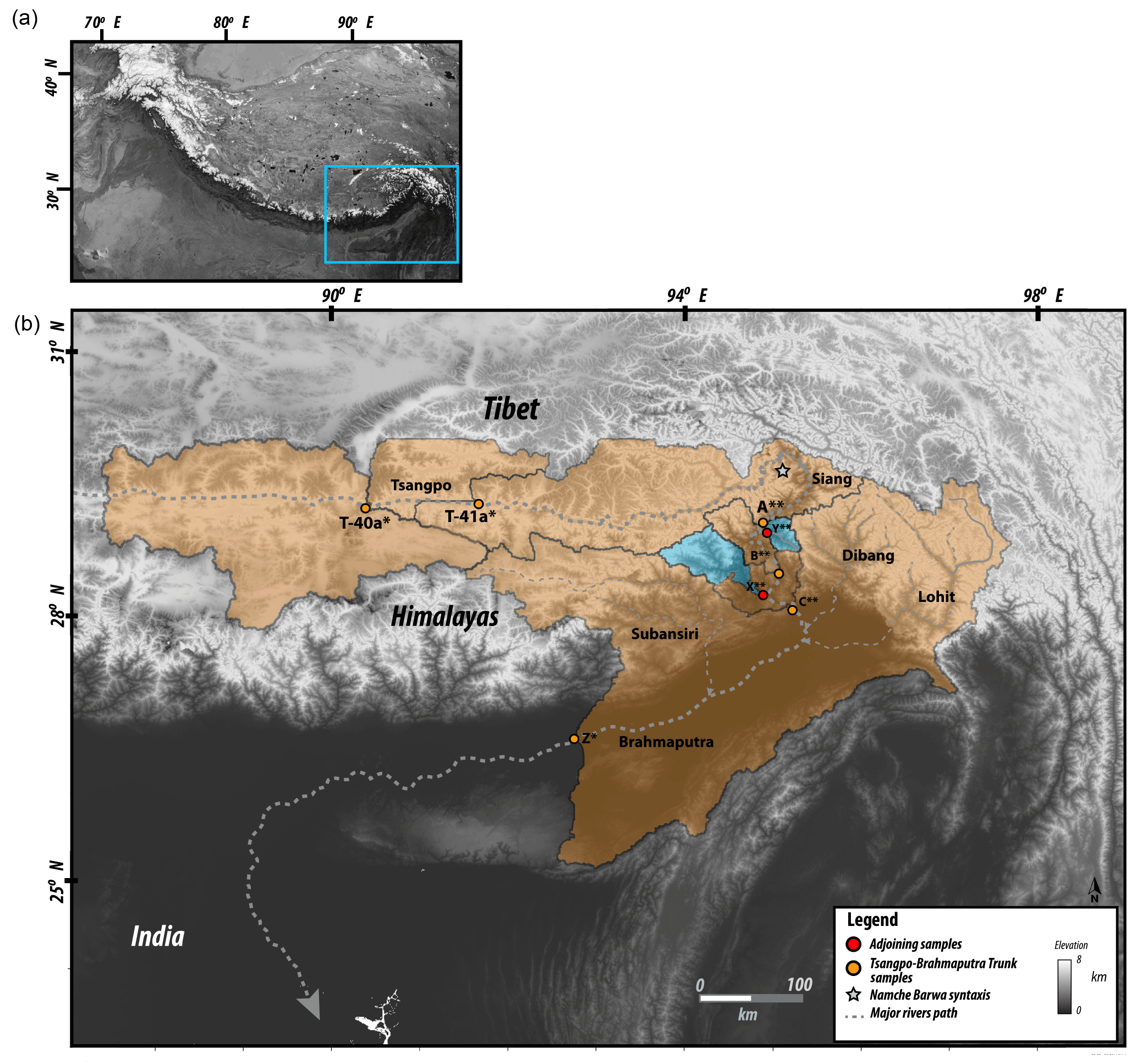
Figure 6(a) Location of the study area and (b) location and name of sampling sites and geometry of the drainage basins contributing to each site. The orange shading represents catchments draining directly into the main trunk; pale blue shading represents the tributary catchments or sub-catchments.
To illustrate the method, we now apply it to a detrital age dataset from the eastern Himalaya that contains ages obtained using the muscovite 40Ar/39Ar thermochronometer. The data were combined from published age datasets collected along the main trunk of the Tsangpo–Siang–Brahmaputra river system, as well as along some of its tributaries (Fig. 6), using age bins given in Table 1. Samples A, B, C (composite sample), X and Y are from Lang et al. (2016) and samples Z, T-40a and T-41a are from Bracciali et al. (2016). The complete age datasets are given in the data repository, Table S1 in the Supplement. In Table 2, we give the relative position of the successive samples along the main trunk of the river, i, the respective exclusive contributing areas, Ai, and the mineral concentration factors, αi. We first used constant values of 1 % (fourth column in Table 2). We will also use variable values for the mineral concentration factors, making the simple assumption that surficial rocks have an average mineral composition that depends mostly on their lithology. A very simple way to proceed is to look at the surface lithology indicated in the geological map of the region for each studied catchment. In this case we used the geologic map of the eastern Himalaya from Yin et al. (2010). The semi-quantitative α values computed for each catchments are given in the fifth column of Table 2. We are aware that, for such a complex and vast area, this approximation can yield poor estimates of the concentration of the target mineral in surface rocks. For more accurate methods (that also require additional data), we refer the user to published work by others that have investigated this issue by looking, for instance, at petrographic and heavy mineral density in modern river sediments, such as the SRD (Source Rock Density) index (Garzanti and Andò, 2007) or the method proposed to compute mineral fertility (Malusà et al., 2016).
We will investigate the effect of using variable concentrations of muscovite-bearing rocks in each of the catchments as derived from a geological map of the area (fifth column in Table 2).
Bracciali et al. (2016)Bracciali et al. (2016)Lang et al. (2016)Lang et al. (2016)Lang et al. (2016)Lang et al. (2016)Lang et al. (2016)Bracciali et al. (2016)Table 2Relative position along the main trunk of the Tsangpo–Siang–Brahmaputra river system. Negative numbers indicate samples collected along a tributary. Catchment areas and mineral concentration factors used to compute the erosion rate reported in Table 7. The two columns correspond to two different sets of values used for comparison. Site names refer to locations shown in Fig. 6.
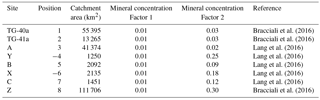
Table 3Predicted erosion rate in the successive sub-catchments obtained by assuming uniform values for the αi and variable values derived from the relative abundance of muscovite-bearing surface rock in the geological map.
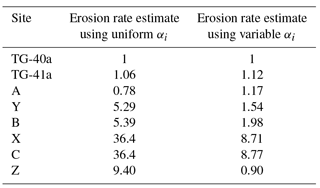
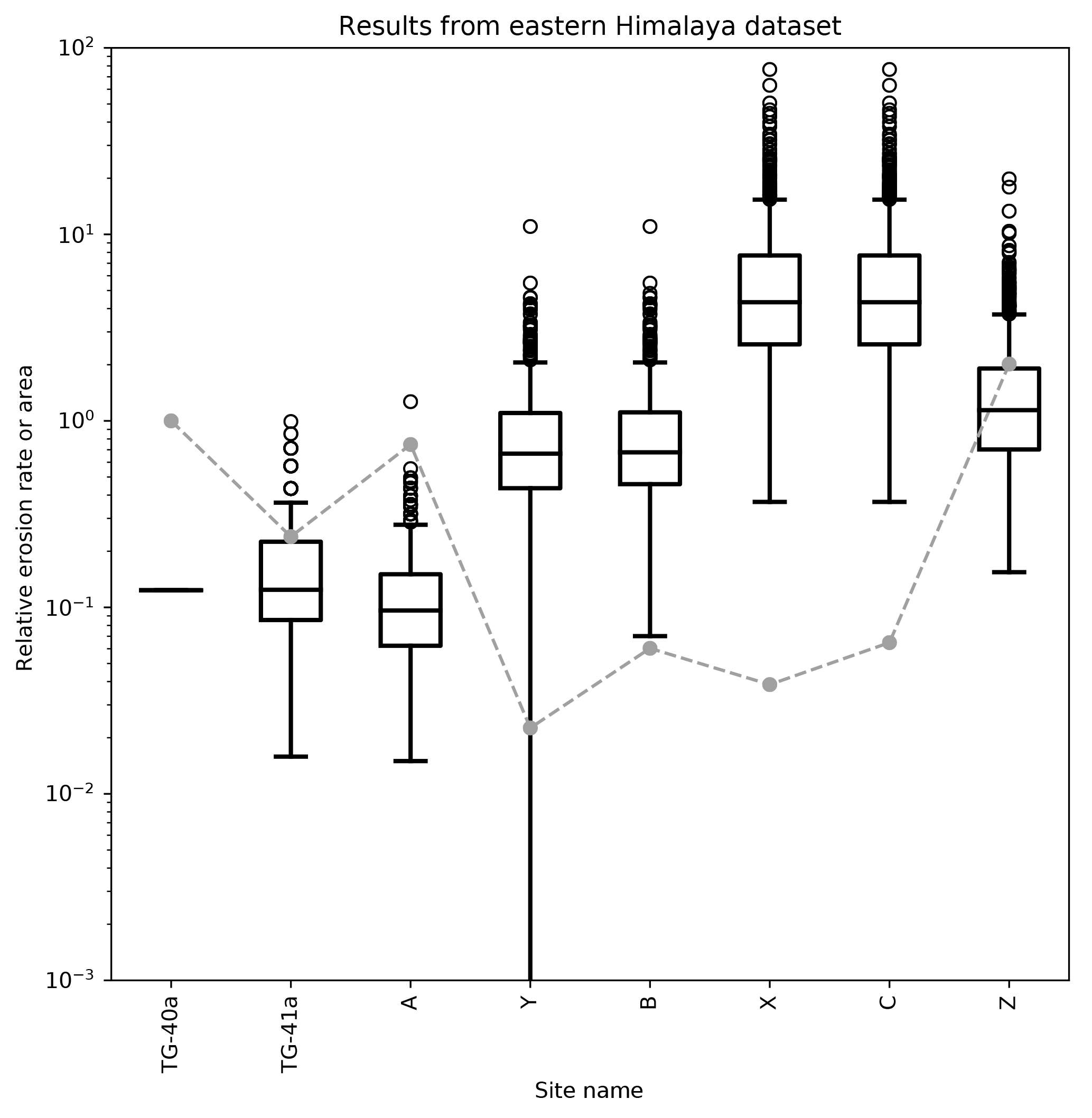
Figure 7Computed erosion rate distributions obtained by applying the method to a Himalayan dataset. For each distribution, the box extends from the lower to upper quartile values, the line corresponds to the median value, and whiskers extend from the box to show the range of the erosion rate estimates, excluding outliers. Outliers are indicated by small circles past the end of the whiskers. Erosion rate values are normalized such that the mean is 1. The gray circles connected by a dashed gray line are the product of the imposed area and mineral concentration factors, Fi=Aiαi, at each site. Site names refer to locations shown in Fig. 6.
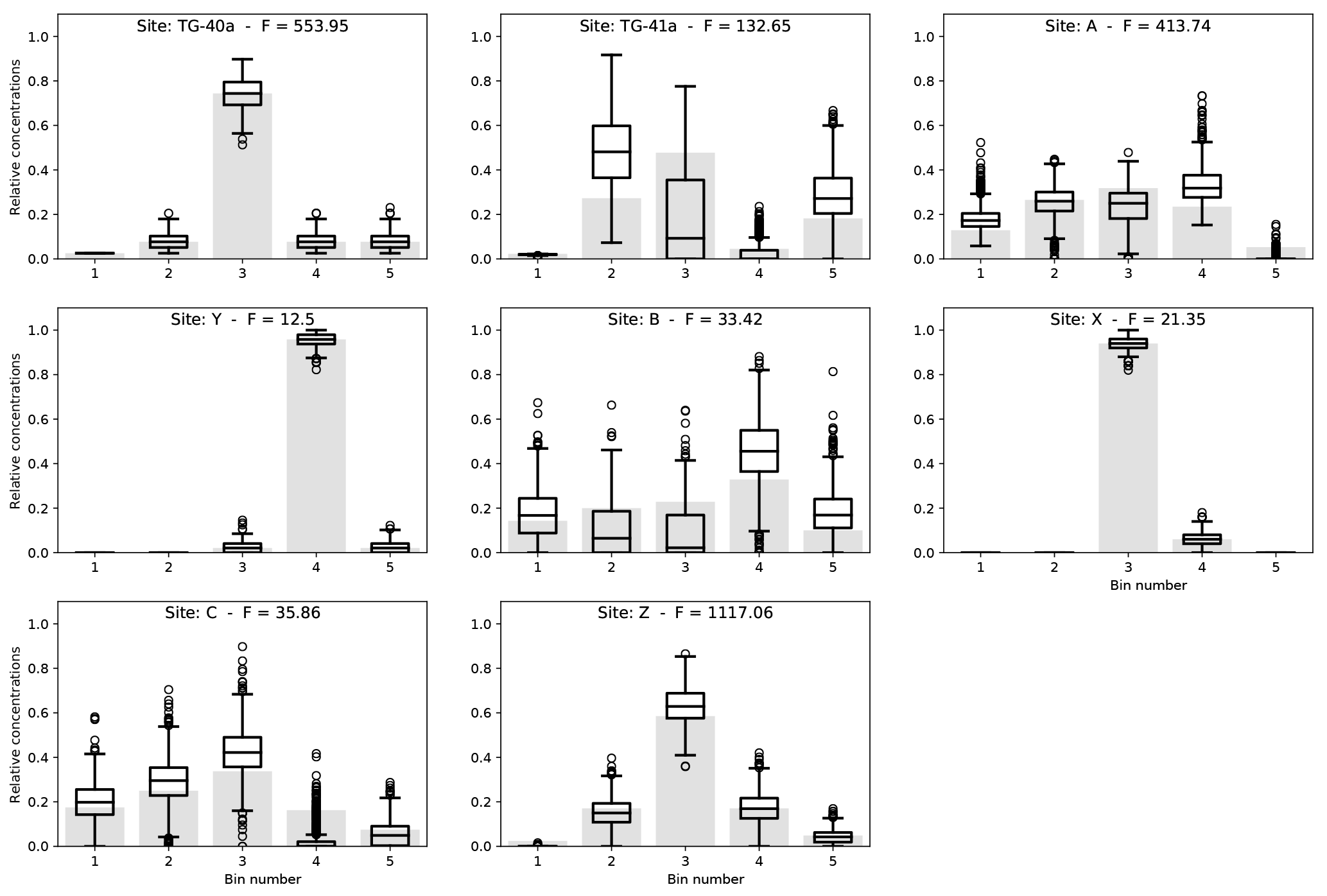
Figure 8Observed distributions of ages (light gray bars) in samples collected at sites shown in Fig. 6 on which the distributions of predicted surface age distributions have been superimposed for each site. For each distribution, the box extends from the lower to upper quartile values, the line corresponds to the median value, and whiskers extend from the box to show the full range, excluding outliers. Outliers are indicated by small circles past the end of the whiskers.
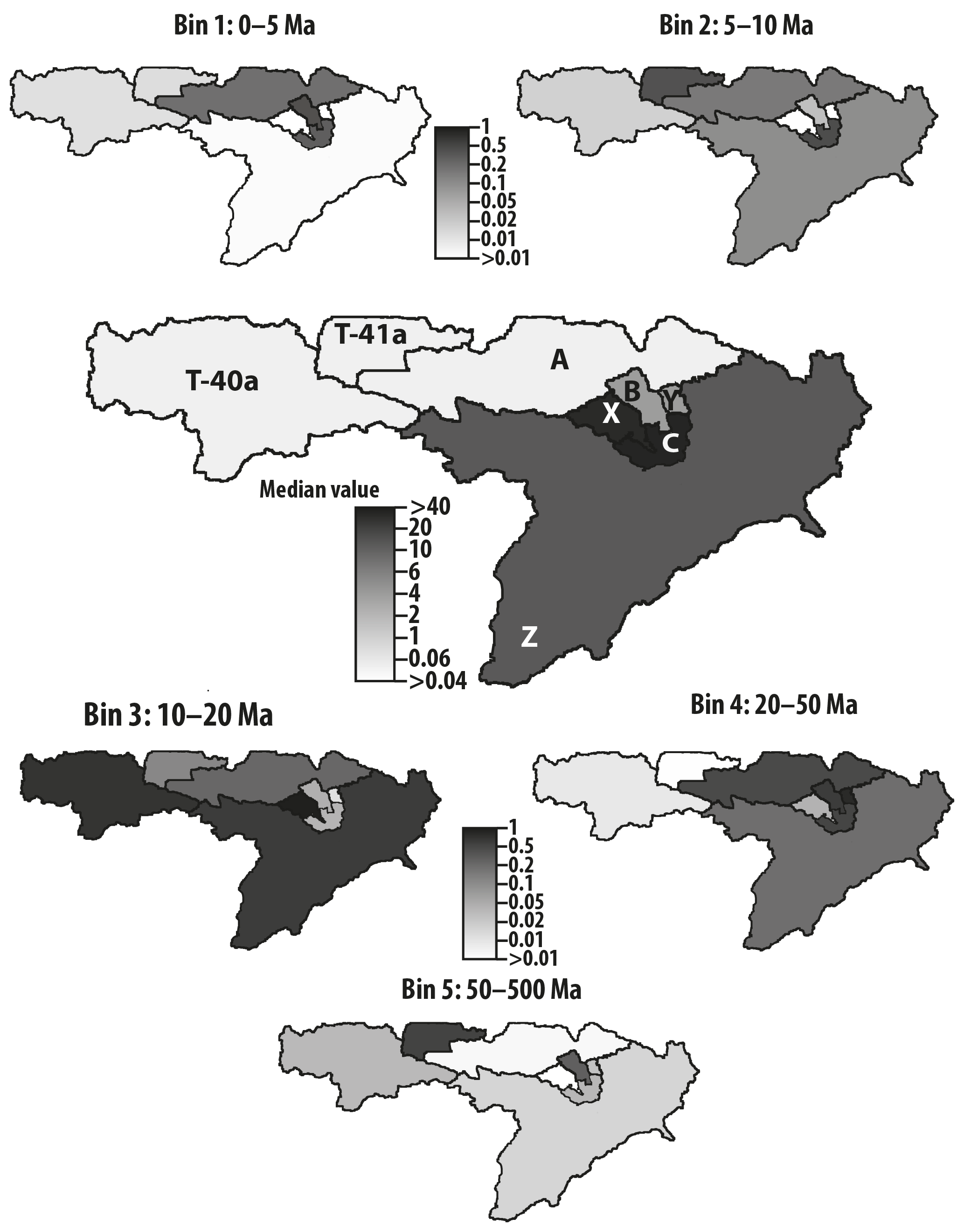
Figure 9Maps of predicted median erosion rates (central panel) and relative surface age concentrations from the muscovite detrital data from eastern Himalaya. See Figs. 8 for full distributions and data.
Results are shown in Fig. 7 as distributions of computed relative minimum erosion rates (i.e., normalized such that the mean erosion rate is 1) obtained by bootstrapping. The computed surface concentrations, , for each site i are shown in Fig. 8. Figure 9 contains maps of the various catchments shaded according to their predicted median erosion rate and surface concentrations of grains of age within each range. Predicted concentrations are scaled such that the sum of the five age bin concentrations is 1 in each catchment. We see that predicted minimum erosion rates increase by about 2 orders of magnitude with distance along the main river trunk from its source area along the southern margin of the Tibetan Plateau. Maximum erosion rates are observed in catchment C (and sub-catchment X), which is closest to the eastern Himalayan syntaxis. The amplitude of the jumps in erosion rate between sites A and B and between B and C are potentially amplified by our method because sites A, B and C have relatively small areas, Ai, and contain relatively uniform distributions of ages among the five bins. As we have noticed in our synthetic examples, this may lead to a spurious increase in erosion rate. Further downstream (catchment Z), the predicted minimum erosion rate remains high but lower than observed near the syntaxis. This estimate is likely to be robust as site Z has a very large contributing area and has an age distribution that is markedly different from that of the previous catchment (C).
The most salient result predicted by the method is that the erosion rate in the eastern Himalayan syntaxis should be at least 5–7× higher than the mean erosion rate along the Tsangpo–Siang–Brahmaputra basin. This estimate is in good agreement with the conclusions of Stewart et al. (2008), who used U-Pb ages of detrital zircon grains from the Brahmaputra River to demonstrate that approximately half of the sediment flux carried by the Brahmaputra River originates from an area around the eastern syntaxis that represents only 2 % of the total area of the river drainage basin. This implies that erosion rate in the vicinity of the syntaxis should be approximately 25× higher than the mean erosion rate. Similar estimates were obtained by Enkelmann et al. (2011) using a larger detrital age dataset from the area, while a relatively smaller estimate (erosion rate should only be 5× higher than the mean in the syntaxis area) was obtained by Singh and France-Lanord (2002) using the isotopic composition of sediments collected along the Brahmaputra River. In Table 3, we compare the erosion rate estimates obtained using uniform surface concentration factors (αi=0.01) with those obtained using variables values (given in the fifth column of Table 2). We note that although the values obtained for the sub-catchments upstream of the syntaxis (sites Y and B) are somewhat reduced, the very large relative erosion rates (5–8× the entire basin average) predicted in the syntaxis (sites X and C) are a robust outcome of the method.
We also note that erosion rates in sub-catchments Y and X do not need to be noticeably smaller than the estimates of erosion rate in their host catchments (B and C). As explained earlier, the true erosion rates could be larger than those of their host catchments. This could be the case for sub-catchment Y, where we predict an erosion rate identical to that of catchment B. These estimates are likely to be reliable because their area is similar to that of their sub-catchment (they occupy a non-negligible portion of their host catchment) and because they have strikingly different age distributions than their host catchments (B and C; Fig. 8). One can also see from the age distributions shown in Fig. 8 how the large contribution from bin 4 at site Y affects the relative height of bin 4 at site B and, similarly, how the large contribution from bin 3 affects the relative height of bin 3 at site C.
Interestingly, there is a good correspondence between present-day erosion rate and where the youngest ages are being generated (sites B and C), with the notable exception of the most downstream catchment (Z). In other words, where the mixing analysis predicts a high minimum erosion rate to account for a substantial change in the age distribution between two adjacent catchments is also where it predicts the highest concentration of young ages in the surface rocks. At the downstream end of the river (Catchment Z), we predict a relatively high minimum erosion rate from the mixing model but a relatively low concentration of young ages in comparison to the other catchments. This could mean that, in catchment Z, the present-day high erosion rate is relatively recent and has not yet led to a complete resetting of cooling ages which were set during earlier events.
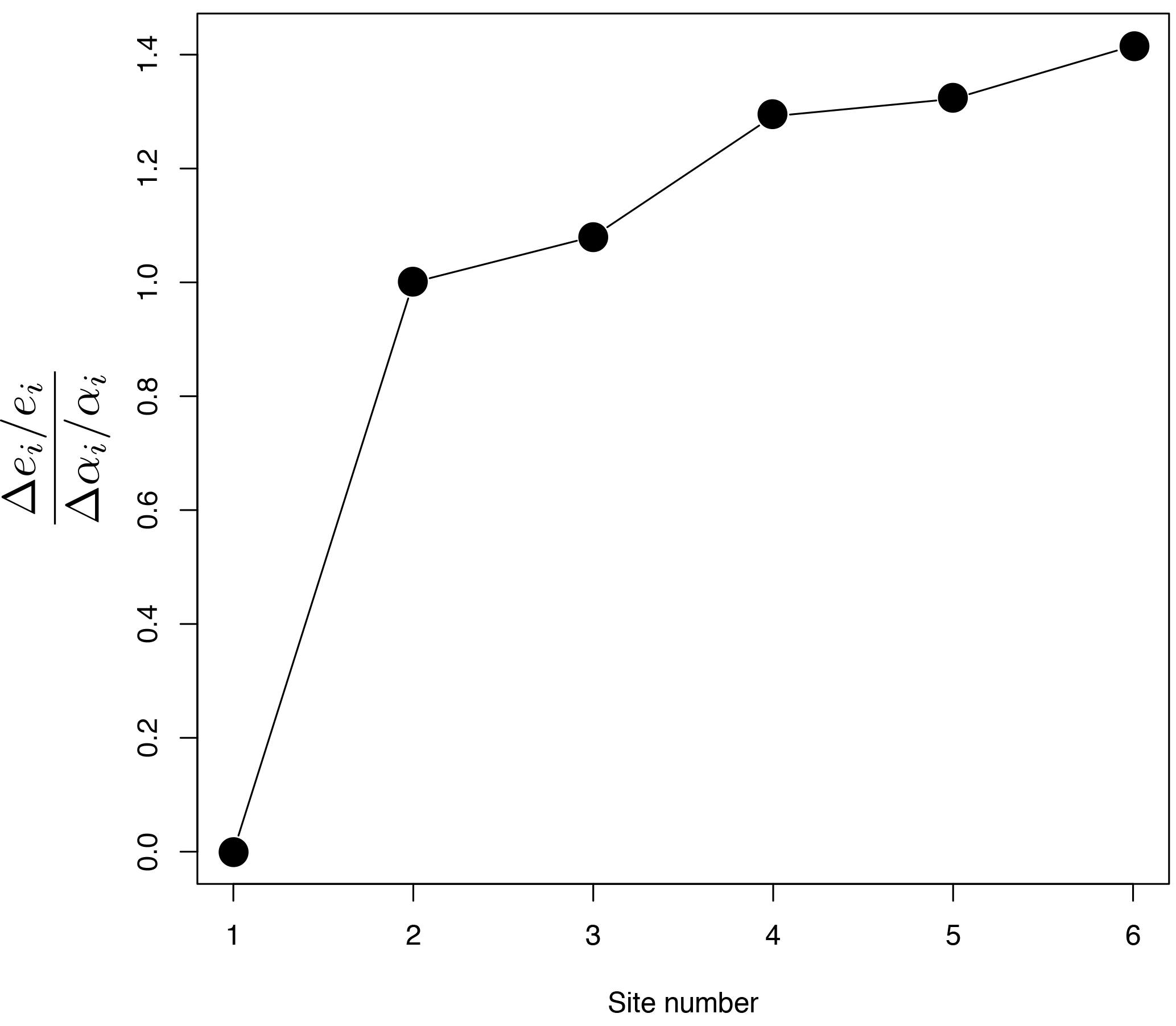
Figure 10Relative uncertainty in erosion rate scaled by the relative uncertainty in mineral concentration factor for the estimates obtained at each of the six sites along the main river trunk. The first site has a fixed relative erosion rate (=1) and therefore no uncertainty.
We also note that the difference between the two quartile values (vertical size of the boxes in Fig. 7 and 8) is large, of the order of 50–100 % of the median value of predicted erosion rate values. This indicates that our method can only provide order-of-magnitude estimates of the minimum erosion rate necessary to explain the age distributions. Interestingly, the difference between the two quartile values does not increase downstream, which demonstrates that the uncertainty introduced by using incomplete or nonrepresentative subsamples of the true distributions at each of the station does not accumulate as our algorithm proceeds from station to station. This results from the incremental nature of our algorithm, as shown by Eq. (11).
One of the sources of uncertainty in our estimates of the erosion rate comes from the assumed value of the mineral concentration factors, αi, which might be difficult to estimate in many situations (Malusà et al., 2016). We can compute the uncertainty on the erosion rates, Δϵi arising from the uncertainty on the mineral concentration factors, Δαi, from
where
The results are shown in Fig. 10 as a plot of the ratio between the relative uncertainty in estimates of erosion rate Δϵi∕ϵi and the relative uncertainty in mineral concentration factors, Δαi∕αi, for the six stations located along the main river trunk. We see that the relative uncertainty in erosion rate is approximately proportional to the relative uncertainty in mineral concentration factor (i.e., all values are close to 1) and that there is only a minor downstream propagation of the uncertainty. This is also a simple consequence of the incremental nature of our algorithm, as explained by Eq. (11).
As described in this paper, our methods relies on the existence of age clusters (or bins) that can be found in the age distributions collected at various sites along a river. The method could be generalized by constructing kernel density estimates of the distribution of ages at each sites. These could be used to estimate the minimum contribution factors, , by applying the condition of Eq. 16 for the complete range of ages, not just the discrete values obtained by binning. We have found, however, that the solution we obtain in this way is strongly dependent on the choice made for the kernel and further investigation of this issue is required. Alternatively, estimates of cumulative density functions could be built directly from the data and, in turn, used to impose condition (Eq. 16) and estimate the minimum contribution factors, . However the limited number of grains at each site makes the comparison between two successive CDFs (cumulative density functions) rather inaccurate. The accuracy of this approach can be tested by increasing the number of bins in our model such that N becomes similar to the average number of grains in any dataset. This leads to an overestimation of the minimum contribution factors. Clearly more work is required to investigate better or alternative ways to compare two successive age distributions.
We have developed a simple method to extract spatially variable erosion rates and surface age distributions from detrital cooling age datasets from modern river sands. The method is based on what we believe are the simplest assumptions necessary to interpret such data and does not rely on a priori knowledge of the distribution of ages in surrounding catchments. In describing the method we have demonstrated that it is suited to extract two apparent sources of information pertaining to the spatial distribution of erosion rate along the river. The first comes from using the age distributions as fingerprints characterizing the areas between two successive sites where detrital samples were collected. This allows us to predict first-order estimates of the relative erosion rate between these areas and the distribution of ages in surficial rocks in each area. These estimates of age distributions can be used as a second independent information on the past and present erosion rate in each area.
By applying the method to an existing dataset from the eastern Himalaya, we show that the method provides estimates of present-day erosion rate patterns in the area that is consistent with previous, independent estimates, potentially evidencing that the fast present-day erosion rates in some parts of the study area are relatively young. We stress, however, that our method can only provide reliable estimates of erosion rate when the age distributions observed at two successive sites are different.
Importantly, the method is limited to providing the spatial distribution of erosion rate; independent information is necessary to transform those into absolute estimates of erosion rate.
We provide a simple implementation of the method in python within a Jupyter Notebook and the data collected from published sources and used in this paper for illustration purposes.
From the definition of the relative contributions, δi,
where
we can write
By performing this operation i−2 times and arbitrarily setting δ1=0, we obtain
The supplement related to this article is available online at: https://doi.org/10.5194/esurf-6-257-2018-supplement.
The authors declare that they have no conflict of interest.
The work leading to the results presented here was supported by the People
Programme (Marie Curie Actions) of the European Union's Seventh Framework
Programme FP7/People/2012/ITN, grant agreement number 316966.
Edited by: Sebastien Castelltort
Reviewed by: Mark Brandon and Marco Giovanni Malusà
Bernet, M., Brandon, M., and Garver, J. I.: Downstream changes of Alpine zircon fission-track ages in the Rhône and Rhine Rivers, J. Sediment Res., 74, 82–94, 2004. a, b
Bracciali, L., Parrish, R. R., Najman, Y., Smye, A., Carter, A., and Wijbrans, J. R.: Plio-Pleistocene exhumation of the eastern Himalayan syntaxis and its domal “pop-up”, Earth Sc. Rev., 160, 350–385, 2016. a, b, c, d
Brandon, M.: Decomposition of fission-track grain-age distributions, Am. J. Sci., 292, 535–564, 1992. a
Braun, J.: Strong imprint of past orogenic events on the thermochronological record, Tectonophysics, 683, 325–332, 2016. a
Brewer, I. D., Burbank, D. W., and Hodges, K. V.: Downstream development of a detrital cooling-age signal: Insights from 40Ar/39Ar muscovite thermochronology in the Nepalese Himalaya, in: Special Paper 398: Tectonics, Climate, and Landscape Evolution, Geological Society of America, 321–338, 2006. a, b
Brown, R.: Backstacking apatite fission track “stratigraphy”: a method for resolving the erosional and isostatic rebound components of tectonic uplift histories, Geology, 19, 74–77, 1991. a
Enkelmann, E. and Ehlers, T. A.: Evaluation of detrital thermochronology for quantification of glacial catchment denudation and sediment mixing, Chem. Geol., 411, 299–309, 2015. a
Enkelmann, E., Ehlers, T. A., Zeitler, P. K., and Hallet, B.: Denudation of the Namche Barwa antiform, eastern Himalaya, Earth Planet. Sc. Lett., 307, 323–333, 2011. a
Garzanti, E. and Andò, S.: Heavy mineral concentration in modern sands: implications for provenance interpretation, Elsevier, Amsterdam, 567–598, 2007. a
Gemignani, L., Sun, X., Braun, J., van Geerve, D., Thomas, R., and Wijbrans, J.: A new detrital mica 40Ar/39Ar dating approach for provenance and exhumation of the Eastern Alps, Tectonics, 36, 1521–1537, 2017. a, b
Gleadow, A. and Brooks, C. K.: Fission track dating, thermal histories and tectonics of igneous intrusions in East Greenland, Contrib. Mineral. Petr., 71, 45–60, 1979. a
Kellett, D. A., Grujic, D., Coutand, I., Cottle, J., and Mukul, M.: The South Tibetan detachment system facilitates ultra rapid cooling of granulite-facies rocks in Sikkim Himalaya, Tectonics, 32, 252–270, 2013. a
Lang, K. A., Huntington, K. W., Burmester, R., and Housen, B.: Rapid exhumation of the eastern Himalayan syntaxis since the late Miocene, Geol. Soc. Am. Bull., 128, 1403–1422, 2016. a, b, c, d, e, f
Malusà, M. G., Resentini, A., and Garzanti, E.: Hydraulic sorting and mineral fertility bias in detrital geochronology, Geol. Rundsch., 31, 1–19, 2016. a, b, c, d, e
McPhillips, D. and Brandon, M.: Using tracer thermochronology to measure modern relief change in the Sierra Nevada, California, Earth Planet. Sc. Lett., 296, 373–383, 2010. a
Resentini, A. and Malusà, M.: Sediment budgets by detrital apatite fission-track dating (Rivers Dora Baltea and Arc, Western Alps), Geol. Soc. Am. Spec. Pap., 487, 125–140, 2012. a, b, c
Ruhl, K. W. and Hodges, K. V.: The use of detrital mineral cooling ages to evaluate steady state assumptions in active orogens: An example from the central Nepalese Himalaya, Tectonics, 24, TC4015, https://doi.org/10.1029/2004TC001712, 2005. a
Sambridge, M. and Compston, W.: Mixture modeling of multi-component data sets with application to ion-probe zircon ages, Earth Planet. Sc. Lett., 128, 373–390, 1994. a
Singh, S. and France-Lanord, C.: Tracing the distribution of erosion in the Brahmaputra watershed from isotopic compositions of stream sediments, Earth Planet. Sc. Lett., 202, 645–662, 2002. a
Stewart, R., Hallett, B., Zeitler, P., Malloy, M., Allen, C., and Trippett, D.: Brahmaputra sediment flux dominated by highly localized rapid erosion from the easternmost Himalaya, Geology, 36, 711–714, 2008. a
Stock, G. M., Ehlers, T. A., and Farley, K. A.: Where does sediment come from? Quantifying catchment erosion with detrital apatite (U-Th)/He thermochronometry, Geology, 34, 725–728, 2006. a
Vermeesch, P.: Quantitative geomorphology of the White Mountains (California) using detrital apatite fission track thermochronology, J. Geophys. Res., 112, FO3004, https://doi.org/10.1029/2006JF000671, 2007. a
Vermeesch, P.: On the visualisation of detrital age distributions, Comput. Geosci., 312, 190–194, 2012. a
Whipp, D. M., Ehlers, T. A., Braun, J., and Spath, C. D.: Effects of exhumation kinematics and topographic evolution on detrital thermochronometer data, J. Geophys. Res., 114, F04021, https://doi.org/10.1029/2008JF001195, 2009. a
Wobus, C. W., Hodges, K. V., and Whipple, K. X.: Has focused denudation sustained active thrusting at the Himalayan topographic front?, Geology, 31, 861–864, 2003. a
Wobus, C. W., Whipple, K. X., and Hodges, K. V.: Neotectonics of the central Nepalese Himalaya: Constraints from geomorphology, detrital 40Ar/39Ar thermochronology, and thermal modeling, Tectonics, 25, TC4011, https://doi.org/10.1029/2005TC001935, 2006. a
Yin, A., Dubey, C., Kelty, T., Webb, A., Harrison, T., Chou, C., and Célérier, J.: Geologic correlation of the Himalayan orogen and Indian craton: Part 2. Structural geology, geochronology, and tectonic evolution of the Eastern Himalaya, Geol. Soc. Am. Bull., 122, 360–395, 2010. a
- Abstract
- Introduction
- The method
- Using age distributions from tributaries
- Assessing the method on synthetic distributions
- Applications to a detrital age dataset
- Mineral concentration factors and their uncertainty
- Ways in which the method could be improved
- Conclusions
- Code and data availability
- Appendix A
- Competing interests
- Acknowledgements
- References
- Supplement
- Abstract
- Introduction
- The method
- Using age distributions from tributaries
- Assessing the method on synthetic distributions
- Applications to a detrital age dataset
- Mineral concentration factors and their uncertainty
- Ways in which the method could be improved
- Conclusions
- Code and data availability
- Appendix A
- Competing interests
- Acknowledgements
- References
- Supplement