the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 16 Jun 2021
| 16 Jun 2021
Rarefied particle motions on hillslopes – Part 3: Entropy
David Jon Furbish
Sarah G. W. Williams
Tyler H. Doane
Theoretical and experimental work (Furbish et al., 2021a, b) indicates that the travel distances of rarefied particle motions on rough hillslope surfaces are described by a generalized Pareto distribution. The form of this distribution varies with the balance between gravitational heating, due to conversion of potential to kinetic energy, and frictional cooling, due to particle–surface collisions; it varies from a bounded form associated with rapid thermal collapse to an exponential form representing isothermal conditions to a heavy-tailed form associated with net heating of particles. The generalized Pareto distribution in this problem is a maximum entropy distribution constrained by a fixed energetic “cost” – the total cumulative energy extracted by collisional friction per unit kinetic energy available during particle motions. That is, among all possible accessible microstates – the many different ways to arrange a great number of particles into distance states where each arrangement satisfies the same fixed total energetic cost – the generalized Pareto distribution represents the most probable arrangement. Because this idea applies equally to the accessible microstates associated with net cooling, isothermal conditions and net heating, the fixed energetic cost provides a unifying interpretation for these distinctive behaviors, including the abrupt transition in the form of the generalized Pareto distribution in crossing isothermal conditions. The analysis therefore represents a novel generalization of an energy-based constraint in using the maximum entropy method to infer non-exponential distributions of particle motions. Moreover, the energetic costs of individual particle motions follow an extreme-value distribution that is heavy-tailed for net cooling and light-tailed for net heating. The relative contribution of different travel distances to the total energetic cost is reflected by the product of the travel distance distribution and the cost of individual particle motions – effectively a frequency–magnitude product.





In two companion papers (Furbish et al., 2021a, b) we examine a theoretical formulation of the probabilistic physics of rarefied particle motions and deposition on rough hillslope surfaces. The formulation is based on a description of the kinetic energy balance of a cohort of particles treated as a rarefied granular gas and a description of particle deposition that depends on the energy state of the particles. The formulation predicts a generalized Pareto distribution of particle travel distances whose form varies with the balance between gravitational heating, due to conversion of potential to kinetic energy, and frictional cooling, due to particle–surface collisions. Specifically, the generalized Pareto distribution varies from a bounded form associated with thermal collapse and rapid deposition to an exponential form representing isothermal conditions to a heavy-tailed form associated with net heating of particles and decreased deposition. The transition to a heavy-tailed form likely involves an increasing conversion of translational to rotational kinetic energy leading to larger travel distances with decreasing effectiveness of collisional friction. As described in Furbish et al. (2021b), these varying forms of the generalized Pareto distribution are consistent with laboratory measurements of particle travel distances reported by Gabet and Mendoza (2012) and Furbish et al. (2021b) and with field-based measurements of travel distances reported by DiBiase et al. (2017) and Roth et al. (2020).
Here we highlight a key point in Furbish et al. (2021a). Namely, the generalized Pareto distribution is not selected in an empirical manner based on goodness-of-fit criteria applied to data sets. Rather, this distribution is dictated by the physics of the problem, just as, for example, the Boltzmann distribution (an exponential distribution) emerges in classical statistical mechanics from consideration of the accessible energy microstates of a gas system. In this problem the versatile form of the generalized Pareto distribution – specifically its apparent success in describing three distinctive energetic behaviors of rarefied particle motions – is enigmatic. Although the different energetic behaviors have a clear mechanical explanation, the transition from a bounded form to a heavy-tailed form in crossing isothermal conditions is abrupt. The basis of this transition, including the upper bound on travel distances prior to transition, is unclear – whether it represents a fundamental change in mechanical behavior or is simply a mathematical curiosity of the generalized Pareto distribution.
The purpose of this third companion paper therefore is to further elaborate the probabilistic physics of particle motions as represented by the generalized Pareto distribution. To do this we appeal to the principle of maximum entropy as outlined in the pioneering work of Jaynes (1957a, b). We specifically demonstrate that in this problem the generalized Pareto distribution is a maximum entropy distribution constrained by a fixed total energetic “cost” – the total cumulative energy extracted by collisional friction per unit kinetic energy available during particle motions. The relative energetic cost locally increases with increasing travel distance for net particle cooling and rapid thermal collapse, it is uniform for isothermal conditions, and it decreases with increasing travel distance for net particle heating. The cumulative cost involves integrating the local cost over the particle travel distance, and the total cumulative cost is then obtained by summing over all particles. This fixed total cost unifies the interpretation of the three energetic behaviors, where the upper bound on travel distances prior to transition is a probabilistic mechanical outcome.
As a point of reference, the canonical example of a maximum entropy distribution is the Boltzmann distribution of the energy states of the particles composing an ordinary gas at thermal equilibrium. Similarly, the Maxwell–Boltzmann distribution of particle speeds, which is derived from the Boltzmann distribution, is a maximum entropy distribution. Here we are referring to the Gibbs entropy of statistical mechanics. A maximum entropy distribution then is the unique distribution that maximizes the Gibbs entropy, subject to constraints imposed on the system. In the canonical case these constraints consist of a fixed number of particles and a fixed total energy, which together guarantee a fixed average energy equal to kBT, where kB is the Boltzmann constant and T is temperature. Moreover, any other distribution of particle energy states satisfying these constraints would coincide with a lower Gibbs entropy.
Jaynes (1957a, b) elaborated the significance of the fact that the Gibbs entropy in statistical mechanics and the Shannon entropy in information theory are essentially one and the same, differing only by a constant. This similarity inspired Jaynes to champion the use of a maximum entropy criterion in choosing a probability distribution, leading to what is now known as the maximum entropy method (a.k.a. MaxEnt or MEM). The key idea of the maximum entropy method, whether viewed as a method of statistical mechanics or as one of inferential statistics, is that it provides an unbiased choice of a distribution by honoring only what is known mechanically about a system. That is, this unbiased choice is a maximally noncommittal choice that is faithful to what we do not know; it is therefore the most reasonable choice in the absence of additional information (Jaynes, 1957a; Williamson, 2010, 25 and 51 pp.). Importantly, mechanical constraints imposed on the system are part of the choice of the distribution, as opposed to empirical fitting without regard to such constraints. The maximum entropy method has been applied in a remarkable variety of fields (Shore and Johnson, 1980; Ramirez and Carta, 2006; Verkley and Lynch, 2009; Singh, 2011; Peterson et al., 2013), including sediment transport (Furbish and Schmeeckle, 2013; Furbish et al., 2016).
In using the maximum entropy method, constraints imposed on the system normally translate to constraints imposed on the moments of the distribution. In this case the method leads to a distribution that is among the exponential family (e.g., exponential, Gaussian). However, applications of the maximum entropy method to non-exponential distributions, including heavy-tailed distributions, are of particular interest in many problems (Peterson et al., 2013). As described below, applying this method to heavy-tailed distributions presents a special challenge in that the first or second moment, or both of these moments, may be undefined for such distributions, including the generalized Pareto distribution (Pickands, 1975; Hosking and Wallis, 1987).
In Sect. 2 we provide background material, namely, the essential elements of the formulation of Furbish et al. (2021a) leading to the generalized Pareto distribution of particle travel distances, and a summary of the properties and derivation of a maximum entropy distribution. In Sect. 3 we describe how the energetic cost associated with collisional friction is expressed as a constraint used in the maximization method. In Sect. 4 we show how the generalized Pareto distribution is obtained as a maximum entropy distribution. In Sect. 5 we describe the probabilistic properties and significance of the energetic cost. We consider the implications of the analysis in the final section. In the fourth companion paper (Furbish and Doane, 2021) we step back and examine the philosophical underpinning of the statistical mechanics framework for describing sediment particle motions and transport.
2.1 Elements of the distribution of travel distances
With reference to Fig. 1, let x denote the particle travel distance with probability density function fx(x). The theoretical formulation (Furbish et al., 2021a) then begins with the particle disentrainment rate function defined by
Here, is the exceedance probability function where Fx(x) is the cumulative distribution function. The disentrainment rate Px(x) may be interpreted as a conditional probability per unit distance. Namely, upon multiplying both sides of Eq. (1) by dx, then is interpreted as the probability that a particle will become disentrained within the small interval x to x+dx, given that it “survived” travel to the distance x. In turn, upon rearranging Eq. (1) and making use of the fact that , the density fx(x) is obtained from
Thus, the significance of the disentrainment rate function becomes clear: it completely determines the density fx(x) via Eq. (2). For reference below, Eqs. (1) and (2) are standard elements of survival (or reliability) analysis, without reference to entropy.
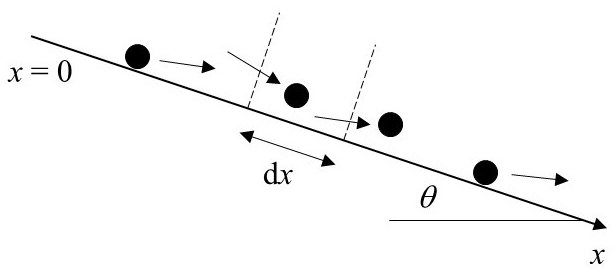
Figure 1Definition diagram of surface inclined at angle θ and control volume with edge length dx through which particles move. Figure reproduced from companion paper (Furbish et al., 2021a).
The particle energy balance formulated in Furbish et al. (2021a) leads to the result that for a given particle size and shape the disentrainment rate on an inclined surface with uniform slope and roughness is
Substituting Eq. (3) into Eq. (2) then leads to the generalized Pareto distribution,
where A∈ℝ is a shape parameter and B>0 is a scale parameter (Pickands, 1975; Hosking and Wallis, 1987). The cumulative distribution is
and the exceedance probability is
For A<1 the mean is
and for the variance is
The mean is undefined for A≥1 and the variance is undefined for .
In mechanical terms the shape and scale parameters A and B are
Here, S is the magnitude of the slope inclined at an angle θ, m is particle mass, g is acceleration due to gravity, μ is a friction factor due to extraction of particle kinetic energy where u is the surface-parallel particle velocity, Ea=〈Ep〉 is the arithmetic average particle energy so that Ea0 is the initial average energy at x=0, where Eh is the harmonic average particle energy, and where α0 and μ1 are factors of order unity and Ki is the Kirkby number defined by
which represents the ratio of gravitational heating to frictional cooling. Here we emphasize that mgcos θ in Eq. (10) is not to be interpreted as the static normal weight of the particle, and μ is not interpreted as a Coulomb-like friction coefficient. Rather, μ∼〈βx〉, where 〈βx〉 denotes the expected proportion of particle kinetic energy extracted per particle–surface collision during downslope motion. Details are provided in Furbish et al. (2021a, b).
For plotting purposes we define a characteristic particle cooling distance and in turn define the following dimensionless quantities denoted by circumflexes:
In addition, a=A and . Then the dimensionless form of the generalized Pareto distribution, Eq. (4), is written as
For a<0 the density is bounded at (Fig. 2). This density increases with for , it is uniform for , and it decreases with x for . It is triangular for . For a=0 the density is exponential. For a>0 this density is heavy-tailed. For a≥1 the mean of is undefined, and for the variance is undefined.
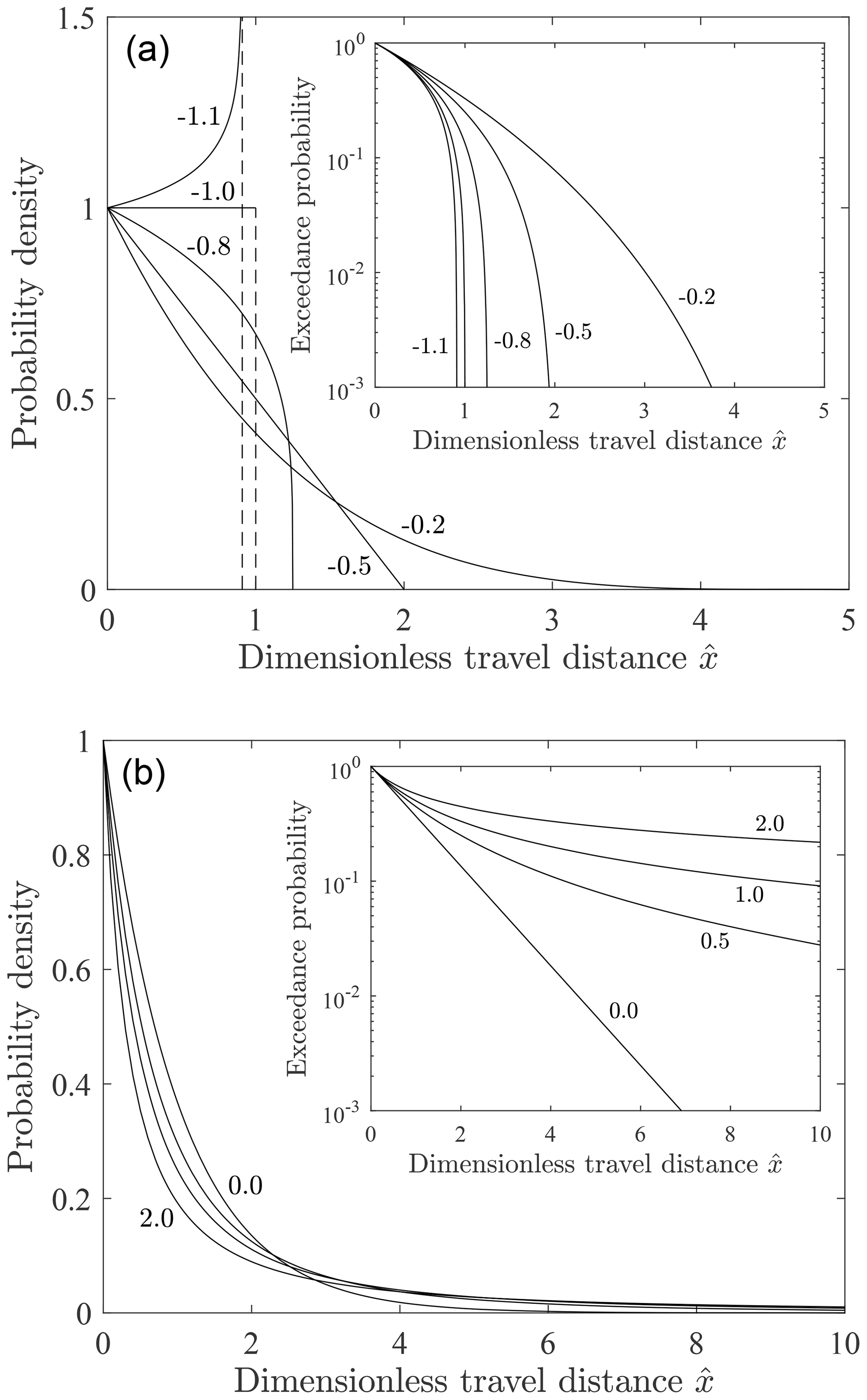
Figure 2Plot of dimensionless probability density versus dimensionless travel distance for scale parameter b=1 and different values of the shape parameter a for (a) a<0 and (b) a≥0 with associated exceedance probability plots (insets). Figure reproduced from companion paper (Furbish et al., 2021a). Compare with Fig. 1 in Hosking and Wallis (1987).
We note that the definition of the differential entropy given in the next section involves the logarithm of the probability density function. In a strict sense this is acceptable only if the density is expressed in dimensionless form as in Eq. (13) or if the definition involves a discrete probability mass function. Nonetheless, the maximization method removes this logarithm such that the outcome is dimensionally the same whether one starts with the dimensional form or the dimensionless form of the density. For simplicity we use the dimensional form, Eq. (4). In addition, for simplicity in plotting we set the scale parameter B=1 in calculated functions containing this parameter, and in several plots we use dimensional abscissa values (e.g., distance x) without reference to units, noting that these have the same visual appearance as if plotted using dimensionless values.
Following Furbish et al. (2021b) we calculate the quantities
Based on Eq. (6), values of the modified exceedance probability R* and the dimensionless travel distance x* should collapse to a straight line in a log −log plot with slope of −1 (Fig. 3). The data in this figure, spanning more than 3 orders of magnitude of the dimensionless travel distance x*, are compiled from Furbish et al. (2021b; Fig. 16 therein). Values of A and B are estimated from laboratory measurements of particle travel distances reported by Gabet and Mendoza (2012) and Furbish et al. (2021b) and from field-based measurements of travel distances reported by DiBiase et al. (2017) and Roth et al. (2020). This plot does not prove, but nonetheless supports, the idea that the generalized Pareto distribution correctly describes the energetics of the behavior of rarefied particle motions for a variety of slope and surface roughness conditions. The data fits for individual experiments with detailed explanation are presented in Furbish et al. (2021b).

Figure 3Plot of modified exceedance probability R* versus dimensionless travel distance x* and line with log −log slope of −1 for laboratory experiments described by Gabet and Mendoza (2012) (green) and Furbish et al. (2021b) (red) and field-based experiments described by DiBiase et al. (2017) (blue) and Roth et al. (2020) (black). Data for A<0 fall to the left of with values in the tails represented by smaller values of x*. Data for A>0 fall to the right of with values in the tails represented by larger values of x*. Total data number is N=5671.
2.2 Maximum entropy distribution
If x denotes a continuous random variable with probability density fx(x) over , then the differential entropy of x is defined as
where it is understood that fx(x)ln fx(x)=0 when fx(x)=0. Given the lineage of this definition, hereafter we follow Peterson et al. (2013) and refer to it as the Boltzmann–Gibbs–Shannon (BGS) entropy. In turn, let gj(x) denote a measurable quantity of x with . We then assume that
with finite aj, where E[ ] denotes the expectation. For example, if , then Eq. (16) gives a0=1. That is, the density fx(x) integrates to unity. If g1(x)=x, then Eq. (16) gives the mean of the distribution, a1=μx. If , then Eq. (16) gives the variance, . Note, however, that gj(x) need not be selected just to obtain the usual moments of a distribution. Indeed, Eq. (16) may represent a constraint imposed by a function gj(x) that does not coincide with a moment of fx(x). As described below, this is essential for heavy-tailed distributions whose first or second moment, or both of these moments, is undefined. The maximum entropy distribution is then given by
where are Lagrange multipliers introduced in the problem of maximizing the entropy H(x) (Appendix A). Moreover, as above we set with a0=1, which guarantees that the probability density fx(x) integrates to unity.
As a point of reference, a fixed mean with g1(x)=x and no other constraint leads to the result
The Lagrange multipliers are then obtained as follows. By the definition of a probability density,
which leads to . Alternatively, Eq. (18) sometimes is presented as (e.g., Tolman, 1938; Schrödinger, 1946; Furbish and Schmeeckle, 2013)
where it becomes clear that is a normalization factor that ensures the probability density integrates to unity. In turn, by the definition of the mean,
which leads to and the exponential distribution,
where it becomes clear that the Lagrange multiplier λ1 enforces the constraint of a fixed mean. The Gaussian distribution is similarly obtained as the maximum entropy distribution with the constraint imposed by a fixed second moment (variance).
The canonical example of the Boltzmann distribution of particle energy states is obtained in this manner as a maximum entropy distribution, where the mean is independently determined to be kBT (e.g., Schrödinger, 1946). The imposed constraints consist of extensive quantities that scale with system size: a fixed number of particles and a fixed total energy, which together guarantee a fixed mean energy. In a similar manner, Furbish and Schmeeckle (2013) and Furbish et al. (2016) derive an exponential distribution for the streamwise velocity states of particles transported as bed load, with the mechanical constraint imposed by a fixed total particle momentum under equilibrium transport conditions.
Our next task is to adapt these ideas to the generalized Pareto distribution, which is not among the exponential family of distributions. We note that there is a continuing effort given to this topic, notably in relation to heavy-tailed (non-exponential) distributions. Peterson et al. (2013) summarize the basis of these efforts and note that one approach for inferring non-exponential distributions is to appeal to nontraditional definitions of the entropy, for example, the Tsallis entropy (Tsallis, 1988), rather than the canonical BGS entropy. The procedure is the same: to maximize the defined entropy subject to an extensive constraint that scales with the system size. Here, however, we adopt the view of Peterson et al. (2013), who highlight the conclusions of Shore and Johnson (1980). Namely, because the BGS definition of entropy uniquely ensures addition and multiplication rules of probability, any other definition of entropy yields a bias in the fitting of data. Peterson et al. (2013) suggest that this offers a “compelling first-principles basis for defining a proper variational principle for modeling distribution functions”. Like these authors in their analysis of the energetics associated with the economics of scale, we retain the BGS definition of entropy and seek a non-extensive energy constraint aligned with the mechanics of the rarefied particle motion problem.
In the canonical example of the Boltzmann distribution, the particle energy state is an instantaneous quantity. Similarly, in the example of bed load particle velocities (Furbish and Schmeeckle, 2013; Furbish et al., 2016), the velocity state is an instantaneous quantity. The state of a particle changes from one instant to the next, and this state can be reached from smaller or larger state values. In these cases, the total particle energy and the total streamwise momentum are well-defined extensive quantities such that the moments of the distributions are fixed. In the absence of additional information, the maximum entropy distribution must be among the exponential family.
In contrast to instantaneous quantities, the particle travel distance x is an integrated quantity that reflects a dynamical particle history starting from the state x=0. The state x must be reached from smaller (unrecorded) state values; it cannot be reached from larger state values. Moreover, travel distances are not like an extensive quantity that scales linearly with the system size. Nonetheless, particle motions require a source of energy and dissipation of energy. Following Peterson et al. (2013) we assume that the outcome of motions – the travel distances x – can be represented in terms of an energetic cost that probabilistically constrains the organization of a great number of particles into accessible states x.
The disentrainment rate Px(x) has special significance in defining the energetic cost. In particular, this rate determines the energetic cost associated with reaching the state x. We start by using Eq. (10) to rewrite Eq. (3) as
The denominator in Eq. (23) describes how the average particle energy Ea(x) varies with x, whether this involves net cooling (A<0), isothermal conditions (A=0) or net heating (A>0). The quantity mgμcos θ in the numerator is the expected spatial rate at which energy is extracted by collisional friction, modulated by the factor . Thus, the disentrainment rate represents the local relative energetic cost – the spatial rate at which particle energy is extracted per unit kinetic energy available during motion at position x.
In turn, the relative energy extracted within a small interval dx is Px(x)dx, so the cumulative energy extracted per unit kinetic energy available is
This is the cumulative energetic cost in reaching position x. For isothermal conditions (A=0) the cumulative cost is
For non-isothermal conditions (A≠0) the cumulative cost is
These two expressions for w(x) converge at small x (Fig. 4). Relative to the linear cumulative cost of isothermal conditions, Eq. (25), the cumulative cost with net cooling (A<0) increases more rapidly up to the limiting distance given by , and the cumulative cost with net heating (A>0) increases more slowly with increasing distance x.
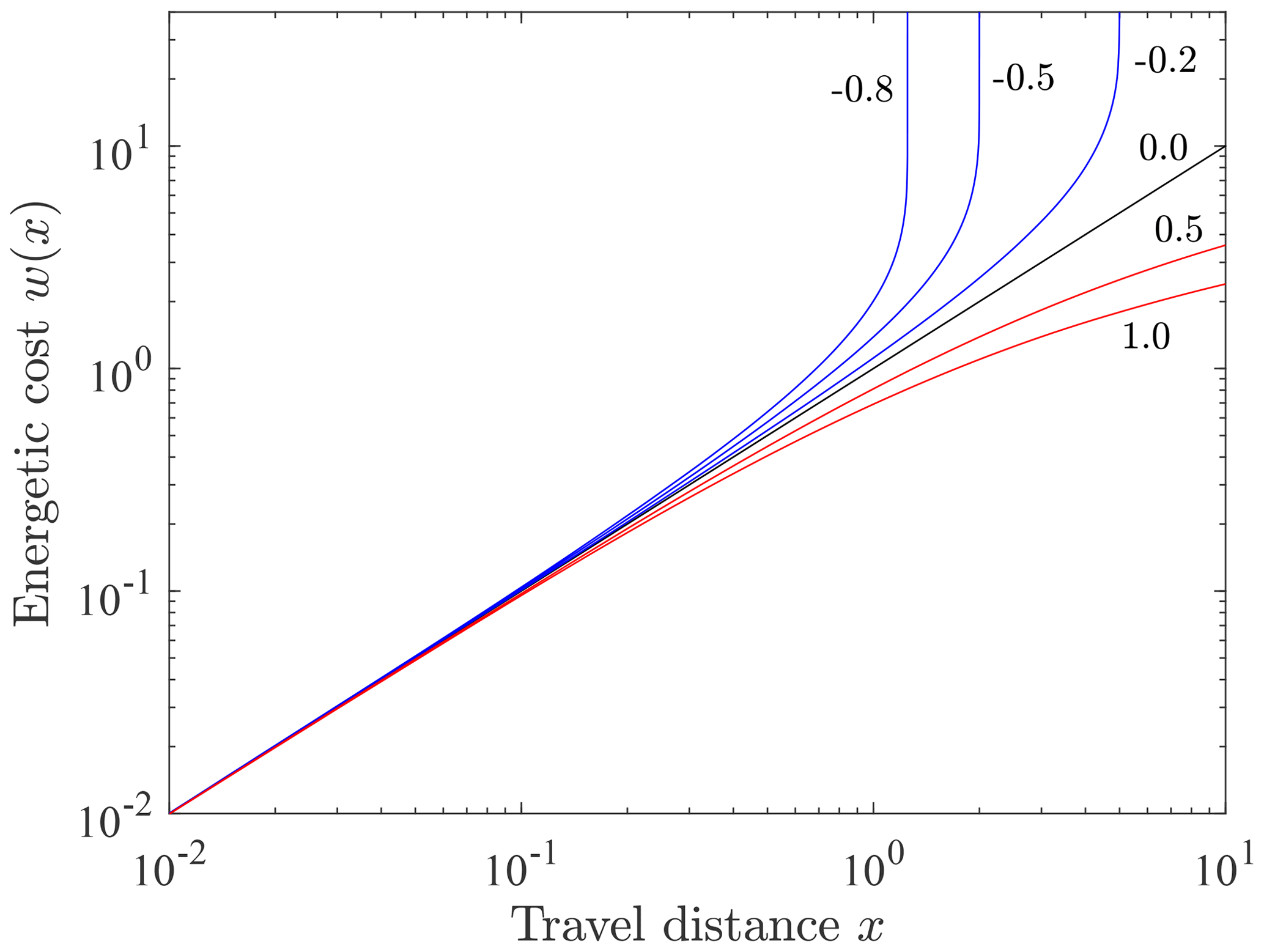
Figure 4Plot of cumulative energetic cost w(x) versus distance x for several values of the shape parameter A representing net cooling (A<0, blue), isothermal conditions (A=0, black) and net heating (A>0, red).
Consider first the isothermal case to illustrate the significance of the cost w(x). This cost increases linearly with the distance x. Let N denote a great number of particles. Among all accessible microstates – the many ways of arranging N particles into states x where each arrangement has a fixed total cost – most microstates involve particles with small state values and fewer with large state values. As shown below, this constraint leads to an exponential distribution. Note that Furbish and Schmeeckle (2013) provide a detailed description of the analysis leading to this outcome, including the basis for counting microstates (see Fig. 3 and Appendix B therein), as applied to particle momentum states rather than travel distance states x. Nonetheless the analysis is otherwise conceptually identical. Tolman (1938) and Schrödinger (1946) provide clear descriptions of the canonical problem (in particular see chap. II, “The Method of the Most Probable Distribution”, in Schrödinger's text).
With non-isothermal conditions and net heating, it is easier to achieve larger state values than with isothermal conditions. Among all accessible microstates, an increasing proportion will have particles in larger states than would be predicted with a uniform cost rate. In contrast, with net cooling a smaller proportion of microstates will have particles in large states x with an increasing relative cost to achieve these large states. Indeed, there is a limit on available energy to be spent in frictional cooling such that the relative cost goes to infinity at . As shown below, these constraints lead to the generalized Pareto distribution.
The energetic cost w(x) is a natural choice for constraining the maximization method. As described in Sect. 6 (“Discussion and conclusions”), this choice is identical in form to the language of “cost” in the economics of scale (Peterson et al., 2013) leading to non-exponential (heavy-tailed) distributions of state values. We use these ideas next in deriving the maximum entropy distribution.
4.1 Constraints
Focusing on the generalized Pareto distribution, as above we start with the constraint given by , namely,
A second, strong mechanical constraint is provided by assuming that the total cumulative energetic cost associated with collisional friction is fixed. Starting with Eq. (24),
which is the cumulative energy extracted by friction per unit kinetic energy available in reaching position x. Then,
which is the average cumulative cost.
Starting with isothermal conditions (A=0), the disentrainment rate . This gives
which shows that the expected cumulative relative cost is unity with μx=B. This is nominally the same as saying that the expected absolute cost is equal to the initial available energy Ea0. More generally with ,
We use these two results in the maximization of entropy.
4.2 Maximization
For isothermal conditions, using Eqs. (27) and (30) maximization leads to (Appendix A)
With and this becomes the exponential distribution,
with B=μx.
More generally, using Eqs. (27) and (31) maximization leads to (Appendix A)
With and this becomes the generalized Pareto distribution given by Eq. (4), thus showing that this distribution is a maximum entropy distribution.
5.1 Cumulative energetic cost
Because of the importance of the energetic cost as a constraint in the maximum entropy method, here we examine the properties of this cost. The cumulative energetic cost w is a monotonic function of the travel distance x according to Eqs. (25) and (26), so we can readily deduce (Appendix B) the probability density function fw(w) of the cost w. For isothermal conditions (A=0) this density is
with mean μw=1. The cumulative distribution is
For non-isothermal conditions (A≠0) the density is
which has attributes of an extreme value distribution. The mean is
where Ei denotes the exponential integral. The cumulative distribution is
Note that these functions depend on the shape parameter A but not on the scale parameter B.
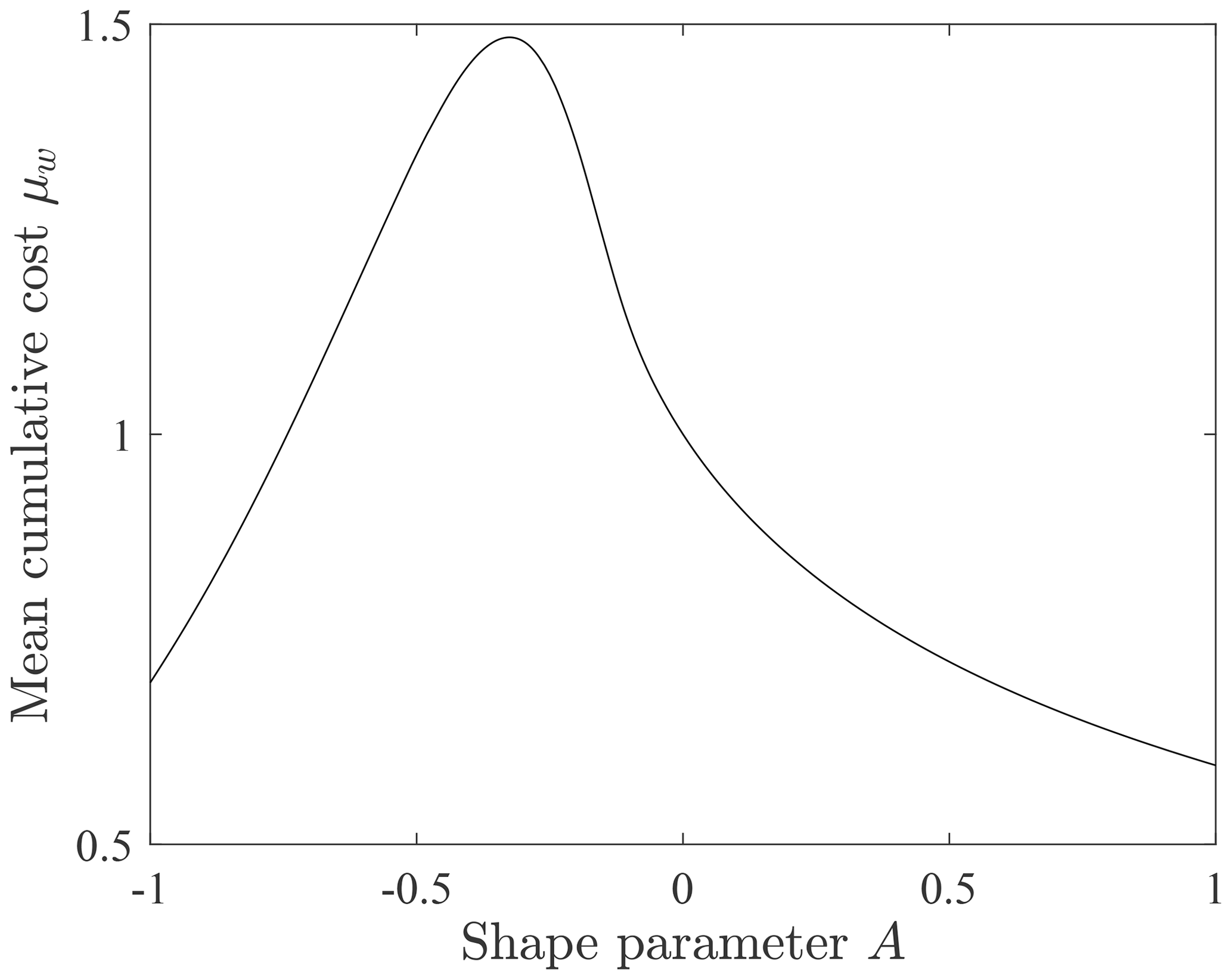
Whereas the generalized Pareto distribution of travel distances x for net cooling (A<0) is bounded at (Fig. 2), the probability density fw(w) of energetic costs w is unbounded (Fig. 5). For isothermal conditions (A=0) the cost w is linearly related to the travel distance x, so the distribution fw(w) has the same exponential form as fx(x). With net cooling (A<0) the distribution fw(w) is heavy-tailed, and with neat heating (A>0) it is light-tailed. With cooling the energetic cost w increases with distance x up to , so probability is shifted to larger values of w. With heating the energetic cost decreases with distance x, so probability is shifted to lower values of w with increasing A. Over the domain the average cost μw has a maximum at an intermediate value of (Fig. 6). For conditions to the left of the maximum the relative costs of motions are large, but the travel distances are small. For conditions to the right of the maximum the travel distances are larger but with smaller relative costs. For conditions of net heating (A>0) the travel distances increase, but the relative costs decrease.
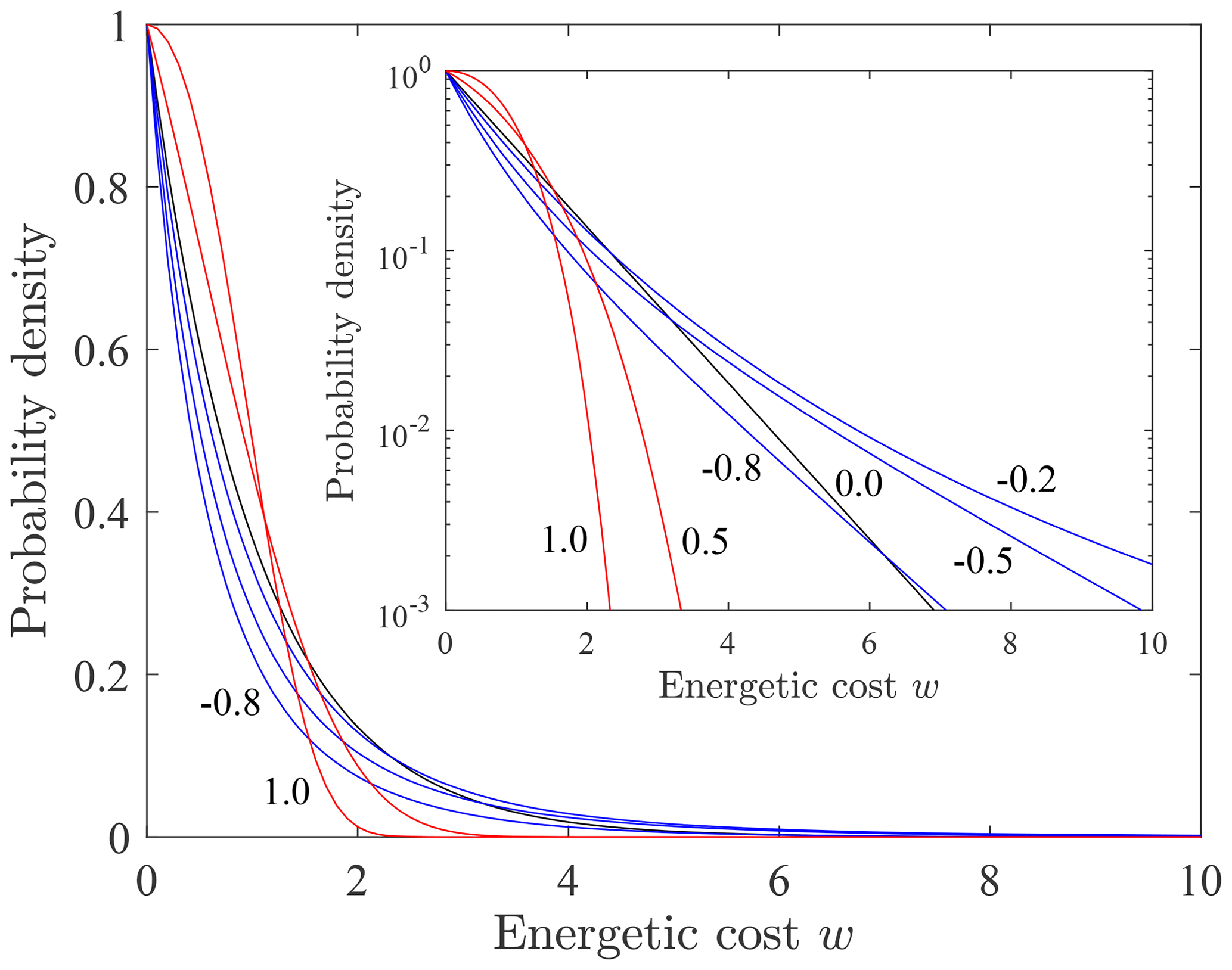
Figure 5Plot of probability density fw(w) of energetic cost w for different values of the shape parameter A, with semi-log plot (inset) showing heavy-tailed form (A<0, blue) and light-tailed form (A>0, red).
The total cumulative cost W(w) up to the value w is
Alternatively, the total cumulative cost up to the distance x is
Expressions for Eqs. (42) and (43) are provided in Appendix B and show how the total costs W(w) and W(x) grow with increasing w and x to a finite value. Consider here the product , which is the total cost per unit travel distance. This function is like a frequency–magnitude product and reflects the relative contribution to the total cost of different parts of the travel distance domain (Fig. 7). For net cooling (A<0) and large negative A the total cost is dominated by the high individual costs of the largest travel distances near the upper bound given by . With increasing A the cost becomes more evenly distributed. At isothermal conditions (A=0) the total cost is dominated by travel distances near the mean distance. For net heating the total cost is dominated by the relatively large individual costs and proportions of small travel distances, although the contribution of large travel distances grows with increasing A.
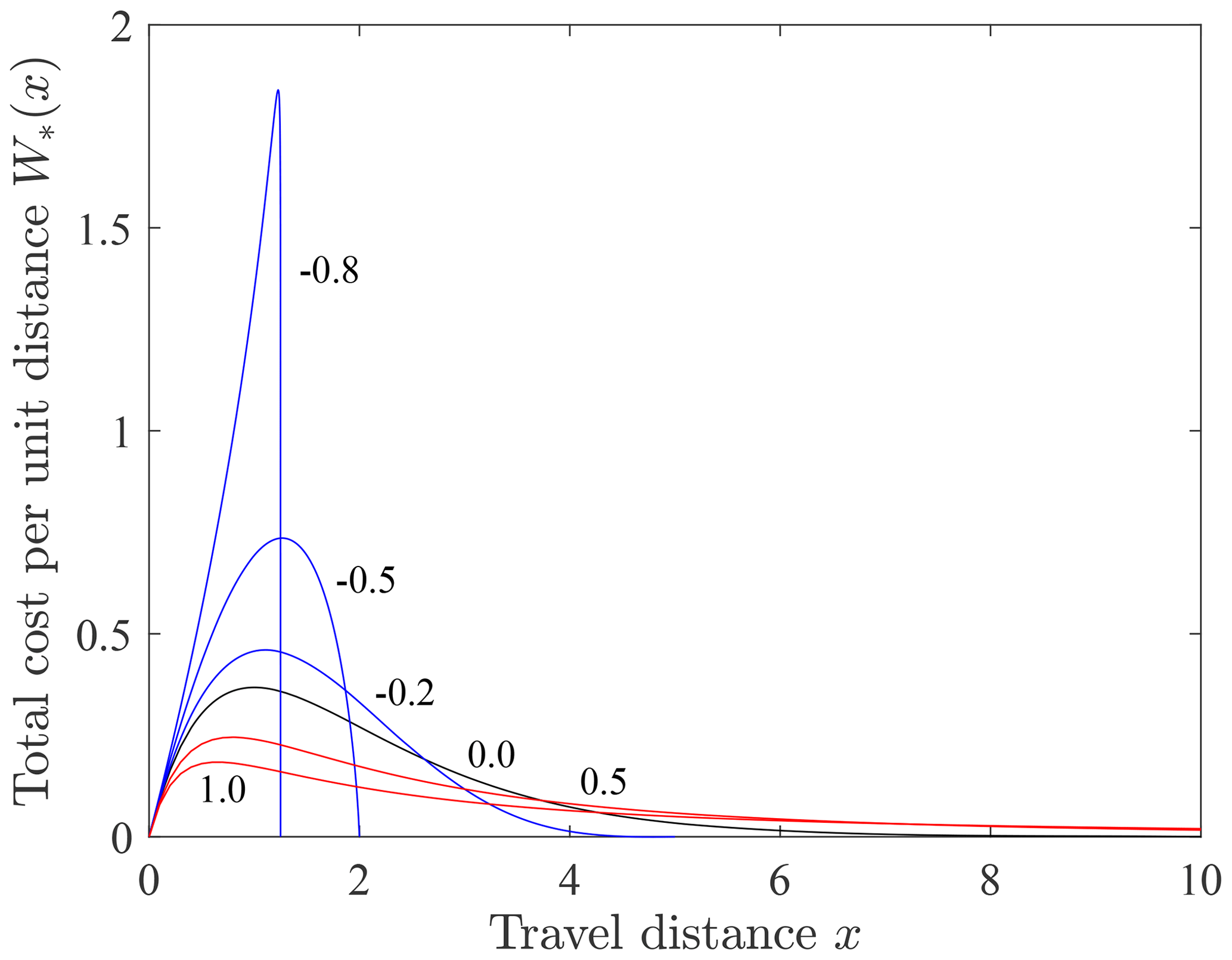
Figure 7Plot of the total cost per unit travel distance W*(x) versus travel distance x for different values of the shape parameter A representing net cooling (A<0, blue), isothermal conditions (A=0, black) and net heating (A>0, red).
5.2 Frictional loss to heat
The energetic cost outlined above pertains to the conversion of translational kinetic energy into other forms, including rotational energy, surface deformation and heat – all under the heading of collisional friction. This cost, however, is not the same as the total energy conversion to heat.
Consider the total energy extracted by friction and ultimately converted to heat. Note first that the quantity mgsin θ at first glance normally is interpreted as the downslope component of the weight of a particle (or control volume) with mass m. In energetic terms, however, this quantity is to be interpreted as the accessible gravitational potential energy per unit downslope travel distance (Furbish et al., 2021a). For an individual particle traveling a distance x the heat generated is
Taking the ensemble average of Eq. (44) and using Eq. (7),
The total heat generated by N particles is then . As a fun point of reference, 100 particles, each with a diameter of 0.1 m and an average starting velocity of 1 m s−1 traveling an average distance of 10 m down a 30∘ slope, produce about 0.32 J of heat – the equivalent of an ordinary 100 W light bulb turned on for 0.0032 s. On the other hand, for a million similar particles traveling an average of 100 m down a 45∘ slope, we must leave the light bulb on for nearly 8 min.
This result offers an example of how application of the maximum entropy method can be misleading. Namely, suppose we assume that a total fixed quantity of heat generated by particle motions, because this is an energetic “cost”, provides a constraint on the maximization procedure. In this situation, and with no further constraints, the maximum entropy method leads to an exponential distribution of heat states qp with mean . Because qp and x are linearly related, then using Eq. (B1) (Appendix B) the distribution fx(x) of travel distances x would be exponential. Note that at this point, however, the mean travel distance μx is not well constrained, as no mechanical information is provided for how particles achieve the distance states x. Whereas the choice of an exponential distribution for is a maximally unbiased choice, it almost certainly is incorrect. We comment further on this type of naïve use of the maximum entropy method below.
Let us acknowledge that a distribution identified as a maximum entropy distribution based on empirically constraining one or more of its moments is not necessarily a special outcome. For example, we frequently fit data to exponential and Gaussian distributions based on estimates of the mean and variance of these distributions – assuming these moments exist and are finite – without reference to maximum entropy. In other words, asserting that a random variable possesses a finite expected value (mean or variance) and then using this assertion to choose the distribution based on the maximum entropy method has no meaningful mechanical significance if the mechanical basis of the constraint is not specified. In this situation a maximum entropy criterion is just one among numerous inferential methods – albeit with the decided merit of being maximally indifferent in the choosing of the distribution. Only when the constraining moment has independent mechanical meaning, and in the absence of additional information, does the label of maximum entropy carry mechanical significance. The example of heat states qp described in Sect. 5.2 illustrates this point.
For example, Furbish et al. (2016) suggest the following:
In focusing on the mechanical side of the duality of Jaynes's principle [of maximum entropy], it becomes important to distinguish between a “strong” mechanical constraint, a “weak” mechanical constraint, and an empirical constraint, as these inform confidence in the resulting choice of a distribution … A strong mechanical constraint is one that derives directly from a dynamics argument … A weak constraint is one that derives from a mechanical definition, for example, an appeal to mass conservation … An empirical constraint is one that appeals to our confidence in suggesting a general behavior from experiments or dimensional analysis but lacks a clear dynamics underpinning.
For rarefied bed load particles transported under equilibrium conditions, Furbish et al. (2016) show that the condition of fixed total particle momentum provides a strong mechanical constraint. In this situation the maximum entropy method predicts an exponential distribution of particle velocities in the absence of any additional mechanical information – consistent with measurements of particle velocities based on high-speed imaging (e.g., Lajeunesse et al., 2010; Roseberry et al., 2012; Furbish and Schmeeckle, 2013; Fathel et al., 2015; Wei et al. 2015). We suggest that the total cumulative energetic cost used herein to constrain the maximum entropy method similarly represents a strong mechanical constraint.
As a point of reference, the analysis presented herein is akin to the energetics associated with the economics of scale as examined by Peterson et al. (2013). To illustrate this idea we start with a binomial expansion of the disentrainment rate, Eq. (3), to give
Momentarily focusing on the leading and first-order terms for illustration, Eq. (46) has the same form as the “communal cost-minus-benefit function” proposed by Peterson et al. (2013, Eg. (5) therein; Appendix C). Using the language of economic costs, here the state x may be interpreted as the size of a community, for example, “particles forming colloidal clusters, or social processes such as people joining cities, citations added to papers, or link creation in a social network” (Peterson et al., 2013, p. 20381). The leading term in Eq. (46) may be interpreted as an intrinsic cost for an individual to achieve (“join”) the state x. For A>0 the first-order term represents a “discount” provided by the community of size x. For A<0 the first-order term represents a “penalty” imposed by the community. If the cost is independent of size (A=0), then the cost rate is fixed () and the maximum entropy method leads to an exponential distribution of states x. If the cost is shared with increasing size (A>0), then the cost of joining the state x decreases with increasing size. This means that larger sizes (states) are more likely to occur than if a discount is not provided, leading to a heavy-tailed distribution of states x. Conversely, if joining a state x involves a penalty (A<0), then exclusion with increasing size occurs, leading to a light-tailed or bounded distribution of states x. In this analysis the idea of cost is fundamentally energetic, whether involving free energy for colloid particles, or the energy consumed by individuals in joining some form of social construct.
When rearranged, the “cost-minus-benefit” function proposed by Peterson et al. (2013) yields a cost function (Appendix C) whose form is identical to that of the disentrainment rate, Eq. (3). In the economics of scale problem the costs are nominally absolute energetic costs. In the problem of rarefied particle motions the cost function (i.e., the disentrainment rate) represents the local relative energetic cost. Nonetheless, the formalism involving a fixed total cumulative cost is essentially the same. With net particle heating it becomes easier for particles to achieve larger states x relative to a fixed local energetic cost, analogous to effects of a discount in the economics of scale. With net cooling this effect is reversed, where the local relative energetic cost increases with the state x. The key mathematical construct of the disentrainment rate, Eq. (3), is that the state x appears in the denominator of this cost function.
In this problem the maximum entropy method in effect considers all possible accessible microstates – the many different ways to arrange a great number of particles into distance states x where each arrangement satisfies the same fixed total energetic cost. (Figure 3 in Furbish and Schmeeckle (2013) illustrates this idea.) Then, the generalized Pareto distribution uniquely represents the most probable arrangement. This idea equally applies to the accessible microstates associated with net cooling, isothermal conditions and net heating. To elaborate this point, consider the upper bound on travel distances, , under conditions of net cooling. This is the distance at which, according to Eq. (23), the expected available kinetic energy goes to zero such that the disentrainment rate Px(x) becomes unbounded. From this perspective, the conditional probability Px(x)dx that motions cease within a small interval dx approaches unity as . However, this is not to be interpreted as a “hard” boundary determined by mechanical behavior. Rather, according to Eq. (26) the cumulative energetic cost becomes unbounded at the distance . For a small upper bound the total energetic cost involves contributions from all particle motions but is dominated by the large individual costs of the largest travel distances near this upper bound (Fig. 7). From this perspective, the bounded form of the distribution is just the most probable among all possible arrangements satisfying the constraint of a fixed total cost, in this case dominated by the individual costs of the largest travel distances. A similar conclusion pertains to the bounded form of the distribution as contributions of individual motions to the total cost become more broadly distributed with increasing A (Fig. 7). In turn, no matter how large the upper bound becomes as approaches zero, this upper bound nonetheless remains finite. The generalized Pareto distribution then “flips” to an exponential form with unbounded distance states only in the limit of . In approaching this limit, the basic physics of particle motions does not change. Similarly, in approaching this limit from the heavy-tailed form of the generalized Pareto distribution, no changes in physics occur. That is, the essence of the balance between gravitational heating and frictional cooling by particle–surface collisions remains the same; there is nothing special or unusual about particle–surface interactions associated with crossing the isothermal transition. Thus, the most probable arrangement of distance states x is in each case – net cooling, isothermal conditions and net heating – a reflection of the unifying probabilistic outcome associated with a fixed total energetic cost.
Here we return to Eq. (2), the standard formulation of the probability density fx(x) presented in survival analysis,
and compare this with the entropy maximization criterion given by
Assuming the Lagrange multiplier , then Eq. (48) becomes
which has the form of Eq. (47) with
Substituting and into Eq. (49) and evaluating the integrals confirms that the generalized Pareto distribution is retrieved.
We now have the interesting result that, for this problem, determining the distribution fx(x) according to Eq. (47) is the same as obtaining this distribution using a maximum entropy criterion. This occurs because the disentrainment rate Px(x) represents an energetic cost to particles reaching states x. Then, inasmuch as the total energetic cost probabilistically constrains the organization of a great number of particles into accessible states consistent with the maximization method, the resulting distribution must be a maximum entropy distribution. If instead the disentrainment rate function Px(x) is heuristically proposed or empirically fitted to data without reference to constraints imposed on the system, then the distribution obtained from Eq. (47) will be consistent with the disentrainment rate function, but this does not guarantee that the distribution is a maximum entropy choice.
The analysis presented here represents an unusual situation. Namely, the generalized Pareto distribution of travel distances and its parametric values are known a priori, and this distribution is then shown to be a maximum entropy distribution consistent with the constraint imposed by a fixed energetic cost. In contrast, normally the distribution is not known and the maximum entropy method is used to choose the distribution in an unbiased manner based on known constraints – as exemplified by the Boltzmann distribution. As emphasized by many, starting with Jaynes (1957a), the maximum entropy method represents a compelling strategy for choosing a distribution. Nonetheless, it is important to highlight the fact that a distribution thus chosen is not necessarily the “correct” distribution (Furbish et al., 2016). Rather, a distribution derived from a maximum entropy criterion is unbiased in that it is faithful to what is known mechanically, but no more; it is the most reasonable choice in the absence of additional information. In this sense the maximum entropy method is a formal application of Occam's razor – an explanation involving the fewest possible assumptions. Thus, the value of showing that the generalized Pareto distribution is a maximum entropy distribution is this: the analysis represents a novel generalization of an energy-based constraint in using the maximum entropy method to infer non-exponential distributions – to include the versatile properties (forms) of the generalized Pareto distribution as applied to the rarefied particle motion problem. Importantly, the analysis uses the BGS definition of entropy rather than a nontraditional definition. We suggest that this result offers promise for examining particle motions in other systems, including particles transported as bed load, where insights involving particle energetics might become useful as we learn more about the physics involved.
The maximization method involves the calculus of variations (Cover and Thomas, 1991), of which a version closer to the original analysis of Boltzmann is presented in Furbish and Schmeeckle (2013) and Furbish et al. (2016). Using the BGS definition of entropy given by Eq. (15) together with the constraints and g1(x) given by Eq. (29), we form the following objective function:
with Lagrange multipliers and λ1. Taking the functional derivative of Eq. (A1) with respect to fx(x) and setting the result to zero then leads to
with . This yields
For isothermal conditions with , Eq. (A3) becomes
With μx=B, evaluating the Lagrange multipliers gives and leading to Eq. (34) in the text. For non-isothermal conditions with , Eq. (A3) becomes
With , evaluating the Lagrange multipliers using l'Hôpital's rule gives and leading to Eq. (4) in the text.
Let x denote a random variable with probability density fx(x). If a random variable w is a monotonic function of x, namely w=g(x), then the probability density fw(w) of w is given by
For isothermal conditions (A=0) the cumulative cost w(x) is
so . Then and the probability density is
The cumulative distribution is
The mean of this distribution is
For non-isothermal conditions (A≠0),
so . Then and
The cumulative distribution is
Noting that for A<0 the limit of Eq. (B6) as is w→∞ and for A>0 the limit as x→∞ is w→∞, then the mean of the distribution is
where Ei denotes the exponential integral.
The total cumulative cost W(w) up to the value w is
For isothermal conditions,
For non-isothermal conditions,
The total cumulative cost W(x) up to the distance x is
For isothermal conditions,
For non-isothermal conditions,
The total cumulative cost W(x) systematically increases with increasing travel distance x (Fig. B1).
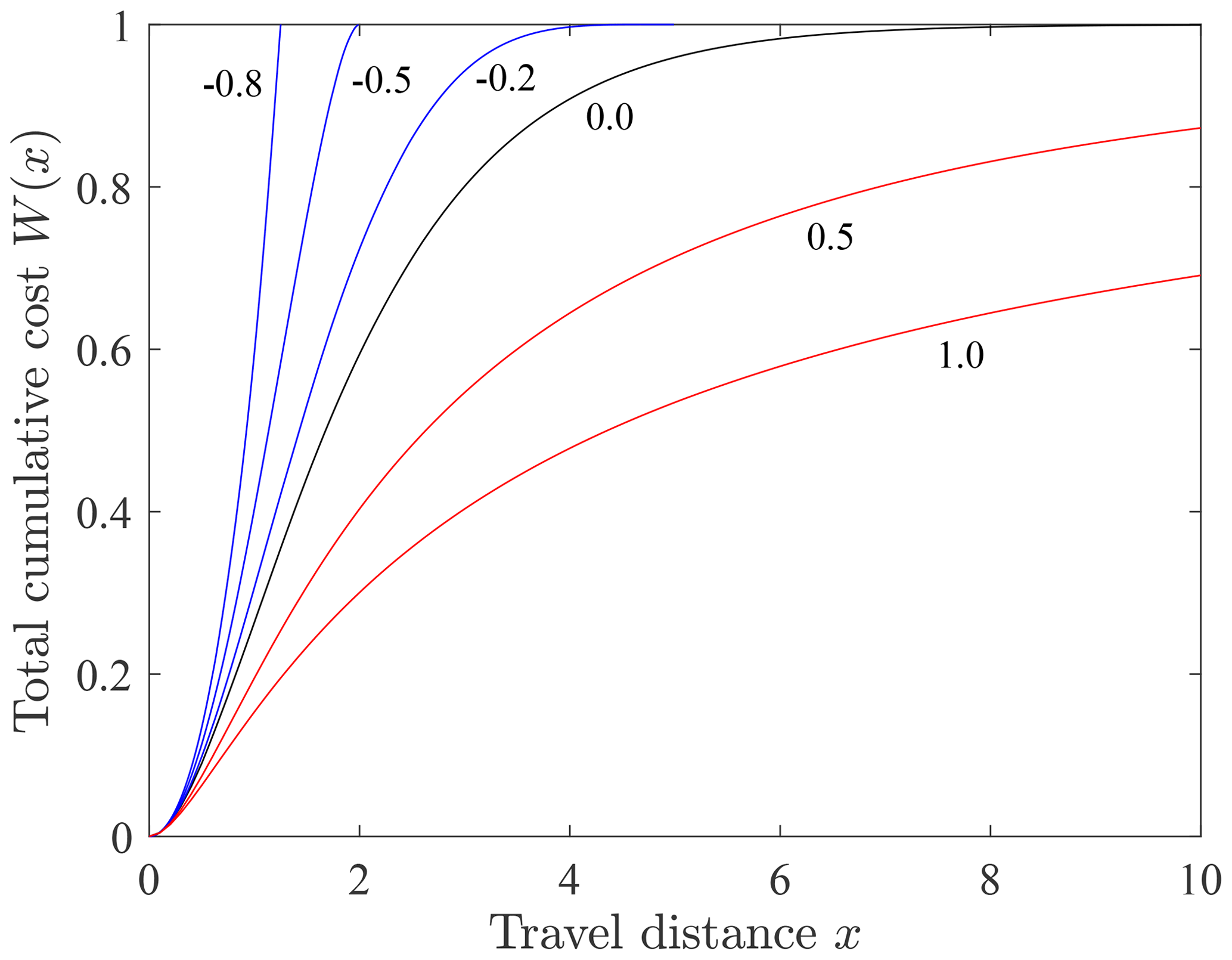
Figure B1Plot of total cumulative cost W(x) versus travel distance x for different values of the shape parameter A representing net cooling (A<0, blue), isothermal conditions (A=0, black) and net heating (A>0, red).
Peterson et al. (2013) focus on discrete systems where the state denotes a community size. Their cost-minus-benefit function has the form
Here,
the quantity on the left side of Eq. (C1) is the total cost-minus-benefit when a particle joins a k-mer community. The joining cost has two components, expressed on the right side: each joining event has an intrinsic cost α0 that must be paid, and each joining event involves some discount that is provided by the community. Because there are k members of the existing community, the quantity is the discount given to a joiner by each existing community particle, where k0 is a problem-specific parameter that characterizes how much of the joining cost burden is shouldered by each member of the community (Peterson et al., 2013).
Rearranging Eq. (C1) then gives
which is analogous to the disentrainment rate function Px(x) given by Eq. (3). The key similarity between Eqs. (C1) and (3) is that k and x are in the denominators of these cost functions.
The data plotted in Fig. 3 are available from sources described in Furbish et al. (2021b).
DJF wrote the paper with critical review and input from SGWW and THD.
The authors declare that they have no conflict of interest.
We appreciate continuing discussions with Peter Haff regarding entropy in Earth-surface systems. Nakul Deshpande offered useful reactions to an earlier draft. We appreciate reviews of our work provided by Joris Heyman and an anonymous referee.
This research has been supported by the National Science Foundation (grant nos. EAR-1420831 and EAR-1735992).
This paper was edited by Eric Lajeunesse and reviewed by Joris Heyman and one anonymous referee.
Cover, T. M. and Thomas, J. A.: Elements of Information Theory, Wiley, New York, 1991.
DiBiase, R. A., Lamb, M. P., Ganti, V., and Booth, A. M.: Slope, grain size, and roughness controls on dry sediment transport and storage on steep hillslopes, J. Geophys. Res.-Earth, 122, 941–960, https://doi.org/10.1002/2016JF003970, 2017.
Fathel, S. L., Furbish, D. J., and Schmeeckle, M. W.: Experimental evidence of statstical ensemble behavior in bed load sediment transport, J. Geophys. Res.-Earth, 120, 2298–2317, https://doi.org/10.1002/2015JF003552, 2015.
Furbish, D. J. and Doane, T. H.: Rarefied particle motions on hillslopes – Part 4: Philosophy, Earth Surf. Dynam., 9, 629–664, https://doi.org/10.5194/esurf-9-629-2021, 2021.
Furbish, D. J. and Schmeeckle, M. W.: A probabilistic derivation of the exponential-like distribution of bed load particle velocities, Water Resour. Res., 49, 1–15, https://doi.org/10.1002/wrcr.20074, 2013.
Furbish, D. J., Schmeeckle, M. W., Schumer, R., and Fathel, S. L.: Probability distributions of bed load particle velocities, accelerations, hop distances, and travel times informed by Jaynes;s principle of maximum entropy, J. Geophys. Res.-Earth, 121, 1373–1390, https://doi.org/10.1002/2016JF003833, 2016.
Furbish, D. J., Roering, J. J., Doane, T. H., Roth, D. L., Williams, S. G. W., and Abbott, A. M.: Rarefied particle motions on hillslopes – Part 1: Theory, Earth Surf. Dynam., 9, 539–576, https://doi.org/10.5194/esurf-9-539-2021, 2021a.
Furbish, D. J., Williams, S. G. W., Roth, D. L., Doane, T. H., and Roering, J. J.: Rarefied particle motions on hillslopes – Part 2: Analysis, Earth Surf. Dynam., 9, 577–613, https://doi.org/10.5194/esurf-9-577-2021, 2021b.
Gabet, E. J. and Mendoza, M. K.: Particle transport over rough hillslope surfaces by dry ravel: Experiments and simulations with implications for nonlocal sediment flux, J. Geophys. Res.-Earth, 117, F01019, https://doi.org/10.1029/2011JF002229, 2012.
Hosking, J. R. M. and Wallis, J. R.: Parameter and quartile estimation for the generalized Pareto distribution, Technometrics, 29, 339–349, 1987.
Jaynes, E. T.: Information theory and statistical mechanics, Phys. Rev., 106, 620–630, 1957a.
Jaynes, E. T.: Information theory and statistical mechanics. II, Phys. Rev., 108, 171–190, 1957b.
Lajeunesse, E., Malverti, L., and Charru, F.: Bed load transport in turbulent flow at the grain scale: Experiments and modeling, J. Geophys. Res.-Earth, 115, F04001, https://doi.org/10.1029/2009JF001628, 2010.
Peterson, J., Dixit, P. D., and Dill, K. A.: A maximum entropy framework for nonexponential distributions, P. Natl. Acad. Sci. USA, 110, 20380–20385, 2013.
Pickands, J.: Statistical inference using extreme order statistics, Ann. Statist., 3, 119–131, 1975.
Ramirez, P. and Carta, J. A.: The use of wind probability distributions derived from the maximum entropy principle in the analysis of wind energy. A case study, Energ. Conserv. Manage., 47, 2564–2577, 2006.
Roseberry, J. C., Schmeeckle, M. W., and Furbish, D. J.: A probabilistic description of the bed load sediment flux: 2. Particle activity and motions, J. Geophys. Res.-Earth, 117, F03032, https://doi.org/10.1029/2012JF002353, 2012.
Roth, D. L., Doane, T. H., Roering, J. J., Furbish, D. J., and Zettler-Mann, A.: Particle motion on burned and vegetated hillslopes, P. Natl. Acad. Sci. USA, 117, 25335–25343, https://doi.org/10.1073/pnas.1922495117, 2020.
Schrödinger, E.: Statistical Thermodynamics, Cambridge University Press, Cambridge, 1946.
Shore, J. and Johnson, R.: Axiomatic derivation of the principle of maximum entropy and the principle of minimum cross-entropy, IEEE T. Inform. Theory, 26, 26–37, 1980.
Singh, V. P.: Derivation of power law and logarithmic velocity distributions using the Shannon entropy, J. Hydrol. Eng., 16, 478–483, https://doi.org/10.1061/(ASCE)HE.1943-5584.0000335, 2011.
Tolman, R. C.: The Principles of Statistical Mechanics, Oxford University Press, New York, 1938.
Tsallis, C.: Possible generalization of Boltzmann-Gibbs statistics, J. Statist. Phys., 52, 479–487, 1988.
Verkley, W. T. M. and Lynch, P.: Energy and enstrophy spectra of geostrophic turbulent flows derived from a maximum entropy principle, J. Atmos. Sci., 66, 2216–2236, https://doi.org/10.1175/2009JAS2889.1, 2009.
Wei, M., Huai, C., Qigang, C., and Danxun, L.: Image-based measurement of bed-load transport in closed channel flow, in: 36th IAHR World Congress, 28 June–3 July 2015, the Hague, the Netherlands, 2015.
Williamson, J.: In Defense of Objective Bayesianism, Oxford University Press, Oxford, UK, 2010.
- Abstract
- Introduction
- Background
- Energetic cost as a maximizing constraint
- Generalized Pareto distribution
- Properties of the energetic cost
- Discussion and conclusions
- Appendix A: Maximization
- Appendix B: Total cumulative cost
- Appendix C: Cost-minus-benefit function of Peterson et al. (2013)
- Data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References
- Article
(2231 KB) - Full-text XML
- Abstract
- Introduction
- Background
- Energetic cost as a maximizing constraint
- Generalized Pareto distribution
- Properties of the energetic cost
- Discussion and conclusions
- Appendix A: Maximization
- Appendix B: Total cumulative cost
- Appendix C: Cost-minus-benefit function of Peterson et al. (2013)
- Data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References